텍스트 버퍼 재구현
2018년 3월 23일, Peng Lyu, @njukidreborn
Visual Studio Code 1.21 릴리스에는 속도 및 메모리 사용량 모두에서 훨씬 더 성능이 향상된 완전히 새로운 텍스트 버퍼 구현이 포함되어 있습니다. 이 블로그 게시물에서는 이러한 개선을 가져온 데이터 구조와 알고리즘을 선택하고 설계한 과정을 이야기하고자 합니다.
JavaScript 프로그램의 성능에 대한 논의는 일반적으로 네이티브 코드로 얼마만큼을 구현해야 하는지에 대한 논의를 수반합니다. VS Code 텍스트 버퍼의 경우, 이러한 논의는 1년 이상 전에 시작되었습니다. 심층적인 탐사를 통해 C++로 텍스트 버퍼를 구현하면 상당한 메모리를 절약할 수 있지만, 기대했던 성능 향상은 얻지 못했습니다. 사용자 지정 네이티브 표현과 V8의 문자열 간의 문자열 변환은 비용이 많이 들고, 우리 경우에는 C++로 텍스트 버퍼 작업을 구현하여 얻은 성능을 저해했습니다. 이 내용은 게시물 끝부분에서 더 자세히 논의하겠습니다.
네이티브로 가지 않기로 결정했으므로 JavaScript/TypeScript 코드를 개선할 방법을 찾아야 했습니다. Vyacheslav Egorov의 이 글과 같은 영감을 주는 블로그 게시물은 JavaScript 엔진의 한계를 밀어붙이고 가능한 한 많은 성능을 짜내는 방법을 보여줍니다. 저수준 엔진 트릭이 없어도 더 적합한 데이터 구조와 더 빠른 알고리즘을 사용하면 속도를 한두 자릿수 이상 개선할 수 있습니다.
이전 텍스트 버퍼 데이터 구조
편집기의 정신 모델은 라인 기반입니다. 개발자는 코드를 한 줄씩 읽고 씁니다. 컴파일러는 라인/컬럼 기반 진단을 제공하고, 스택 트레이스에는 라인 번호가 포함되며, 토큰화 엔진은 라인별로 실행되는 등입니다. 간단하지만 VS Code를 구동하는 텍스트 버퍼 구현은 Monaco 프로젝트를 시작한 첫날 이후로 크게 변경되지 않았습니다. 우리는 라인 배열을 사용했으며, 일반적인 텍스트 문서는 상대적으로 작기 때문에 꽤 잘 작동했습니다. 사용자가 입력할 때, 우리는 배열에서 수정할 라인을 찾아 대체했습니다. 새 라인을 삽입할 때, 라인 배열에 새 라인 객체를 삽입하고 JavaScript 엔진이 그 작업을 처리했습니다.
하지만 특정 파일을 열 때 VS Code에서 메모리 부족(Out-Of-Memory) 오류가 발생하는 보고가 계속 들어왔습니다. 예를 들어, 한 사용자는 35MB 파일을 열지 못했습니다. 근본 원인은 파일에 라인이 너무 많았다는 것인데, 1370만 개였습니다. 각 라인마다 `ModelLine` 객체를 생성했고, 각 객체는 약 40-60바이트를 사용했으므로 라인 배열은 문서를 저장하기 위해 약 600MB의 메모리를 사용했습니다. 이는 초기 파일 크기의 약 20배에 달하는 수치였습니다!
라인 배열 표현의 또 다른 문제는 파일 열기 속도였습니다. 라인 배열을 구성하기 위해 줄 바꿈 문자로 콘텐츠를 분할해야 했으므로 라인당 문자열 객체를 얻게 됩니다. 이 자체 분할이 성능에 해를 끼치는데, 이는 나중에 벤치마크에서 확인할 수 있습니다.
새로운 텍스트 버퍼 구현 찾기
이전의 라인 배열 표현은 생성하는 데 시간이 많이 걸리고 많은 메모리를 소비하지만, 라인 조회는 빠릅니다. 이상적인 세상에서는 텍스트 파일 내용만 저장하고 추가 메타데이터는 저장하지 않을 것입니다. 따라서 메타데이터가 덜 필요한 데이터 구조를 찾기 시작했습니다. 다양한 데이터 구조를 검토한 후, 피스 테이블(piece table)이 시작하기에 좋은 후보가 될 수 있음을 알게 되었습니다.
피스 테이블을 사용하여 너무 많은 메타데이터 피하기
피스 테이블은 텍스트 문서(TypeScript 소스 코드)에 대한 일련의 편집을 나타하는 데 사용되는 데이터 구조입니다.
class PieceTable {
original: string; // original contents
added: string; // user added contents
nodes: Node[];
}
class Node {
type: NodeType;
start: number;
length: number;
}
enum NodeType {
Original,
Added
}
파일이 처음 로드된 후, 피스 테이블은 `original` 필드에 전체 파일 내용을 포함합니다. `added` 필드는 비어 있습니다. `NodeType.Original` 타입의 노드가 하나 있습니다. 사용자가 파일 끝에서 입력하면, 새 내용을 `added` 필드에 추가하고, 노드 목록 끝에 `NodeType.Added` 타입의 새 노드를 삽입합니다. 마찬가지로, 사용자가 노드 중간에서 편집하면 해당 노드를 분할하고 필요한 새 노드를 삽입합니다.
아래 애니메이션은 피스 테이블 구조에서 문서를 라인별로 액세스하는 방법을 보여줍니다. 두 개의 버퍼(`original` 및 `added`)와 세 개의 노드(이는 `original` 콘텐츠 중간에 삽입한 결과입니다)가 있습니다.
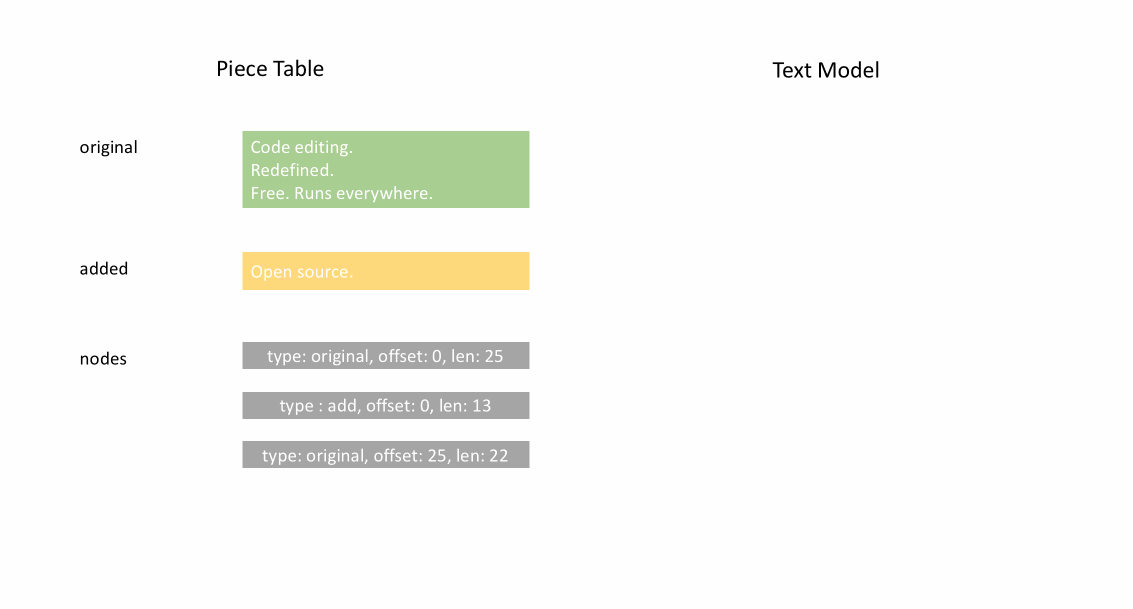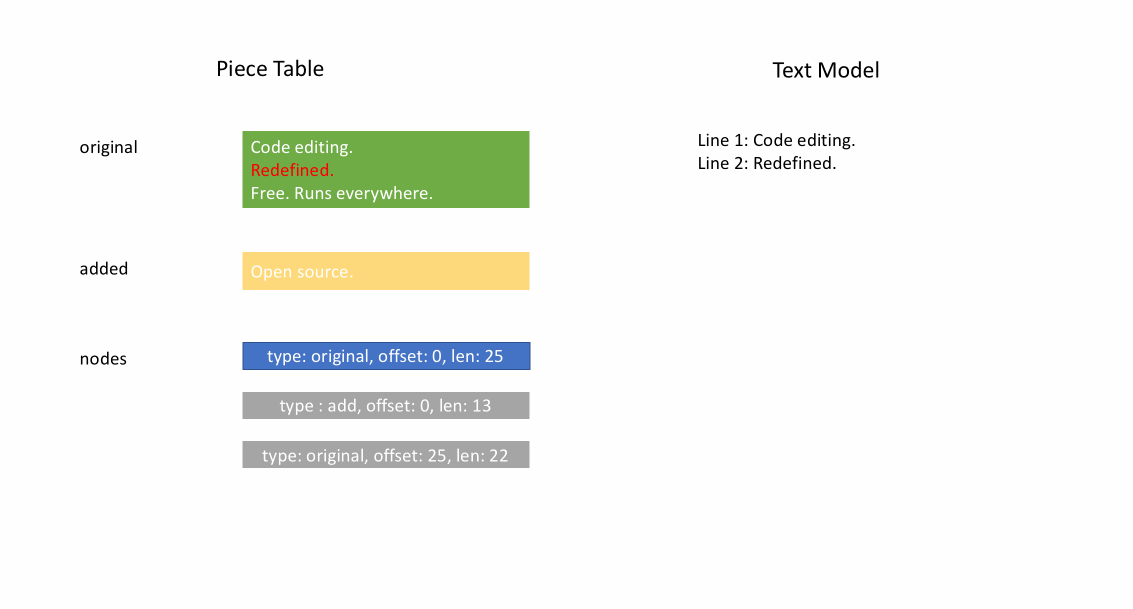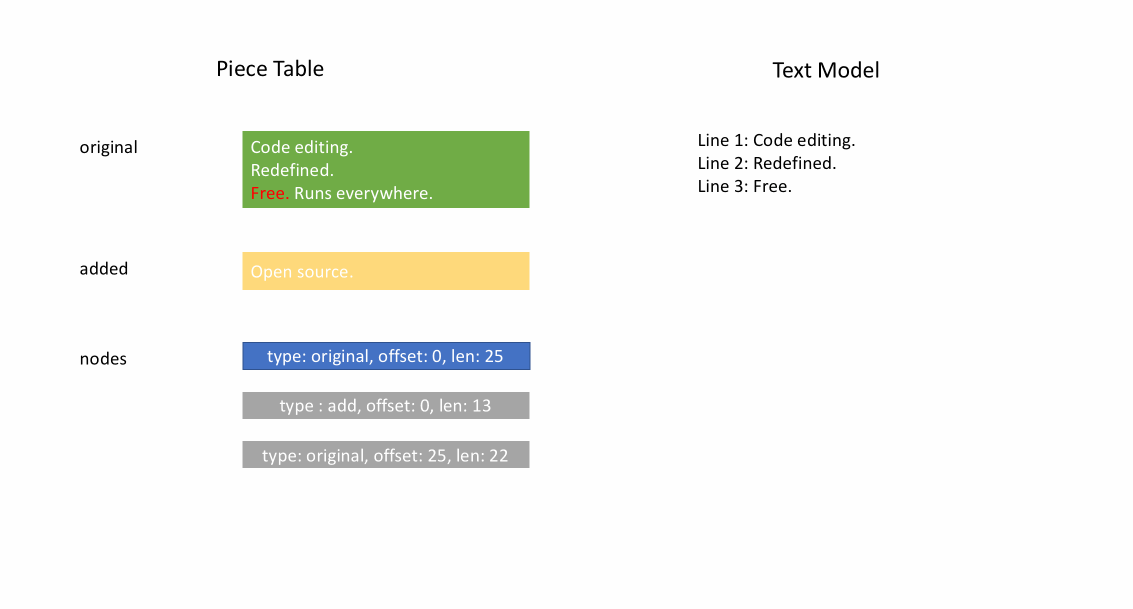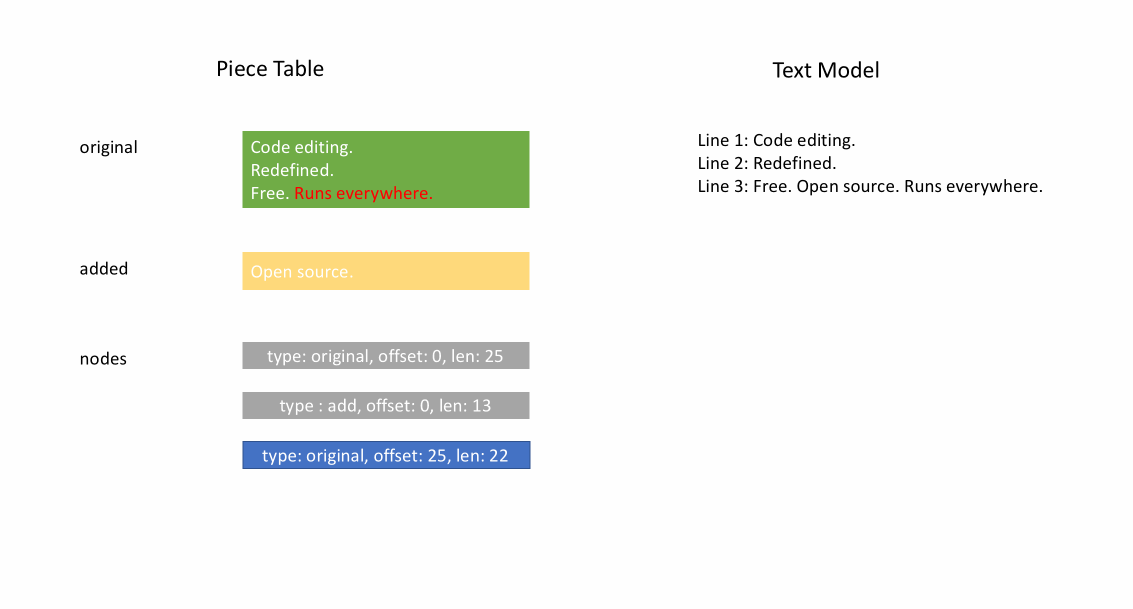
피스 테이블의 초기 메모리 사용량은 문서 크기에 가깝고, 수정을 위해 필요한 메모리는 편집 횟수와 추가된 텍스트에 비례합니다. 따라서 일반적으로 피스 테이블은 메모리를 효율적으로 사용합니다. 그러나 낮은 메모리 사용량의 대가는 논리적 라인에 액세스하는 것이 느리다는 것입니다. 예를 들어, 1000번째 라인의 내용을 얻으려면 문서 시작부터 모든 문자를 반복하여 첫 999개의 줄 바꿈 문자를 찾아 각 문자를 다음 줄 바꿈 문자까지 읽는 것 외에는 방법이 없습니다.
더 빠른 라인 조회를 위해 캐싱 사용
전통적인 피스 테이블 노드는 오프셋만 포함하지만, 라인 콘텐츠 조회를 더 빠르게 만들기 위해 줄 바꿈 정보를 추가할 수 있습니다. 줄 바꿈 위치를 저장하는 직관적인 방법은 노드 텍스트에 포함된 각 줄 바꿈 문자의 오프셋을 저장하는 것입니다.
class PieceTable {
original: string;
added: string;
nodes: Node[];
}
class Node {
type: NodeType;
start: number;
length: number;
lineStarts: number[];
}
enum NodeType {
Original,
Added
}
예를 들어, 특정 `Node` 인스턴스에서 두 번째 라인에 액세스하려면 `node.lineStarts[0]`과 `node.lineStarts[1]`을 읽으면 라인이 시작되고 끝나는 상대 오프셋을 얻을 수 있습니다. 노드가 몇 개의 줄 바꿈 문자를 가지고 있는지 알고 있으므로, 문서에서 임의의 라인에 액세스하는 것은 간단합니다. 첫 번째 노드부터 시작하여 대상 줄 바꿈 문자를 찾을 때까지 각 노드를 읽으면 됩니다.
알고리즘은 여전히 간단하며, 이전보다 더 잘 작동합니다. 이제 문자 단위로 반복하는 대신 전체 텍스트 덩어리를 건너뛸 수 있습니다. 나중에 이를 더 개선할 수 있다는 것을 알게 될 것입니다.
문자열 연결 함정 피하기
피스 테이블은 두 개의 버퍼를 보유합니다. 하나는 디스크에서 로드된 원본 콘텐츠용이고, 다른 하나는 사용자 편집용입니다. VS Code에서는 Node.js `fs.readFile`을 사용하여 텍스트 파일을 로드하며, 이는 64KB 청크 단위로 콘텐츠를 제공합니다. 따라서 파일이 예를 들어 64MB이면 1000개의 청크를 받게 됩니다. 모든 청크를 받은 후, 이를 하나의 큰 문자열로 연결하여 피스 테이블의 `original` 필드에 저장할 수 있습니다.
V8이 문제를 일으키기 전까지는 합리적으로 들립니다. 500MB 파일을 열려고 시도했지만, 제가 사용했던 V8 버전에서는 최대 문자열 길이가 256MB였기 때문에 예외가 발생했습니다. 이 제한은 향후 V8 버전에서는 1GB로 늘어나겠지만, 실제로 문제를 해결하지는 못합니다.
`original` 및 `added` 버퍼를 보유하는 대신, 버퍼 목록을 보유할 수 있습니다. 이 목록을 짧게 유지하려고 노력하거나 `fs.readFile`에서 받는 것을 참고하여 문자열 연결을 피할 수 있습니다. 디스크에서 64KB 청크를 받을 때마다 `buffers` 배열에 직접 푸시하고 이 버퍼를 가리키는 노드를 생성합니다.
class PieceTable {
buffers: string[];
nodes: Node[];
}
class Node {
bufferIndex: number;
start: number; // start offset in buffers[bufferIndex]
length: number;
lineStarts: number[];
}
균형 이진 트리를 사용하여 라인 조회 속도 향상
문자열 연결을 해결했으므로 이제 대용량 파일을 열 수 있지만, 이는 또 다른 잠재적인 성능 문제로 이어집니다. 예를 들어 64MB 파일을 로드한다고 가정하면, 피스 테이블에는 1000개의 노드가 있습니다. 각 노드에 줄 바꿈 위치를 캐싱하더라도, 어떤 절대 라인 번호가 어떤 노드에 있는지 알 수 없습니다. 라인 콘텐츠를 얻으려면 해당 라인을 포함하는 노드를 찾을 때까지 모든 노드를 통과해야 합니다. 우리 예시에서는 찾으려는 라인 번호에 따라 최대 1000개의 노드를 반복해야 합니다. 따라서 최악의 경우 시간 복잡도는 O(N)입니다(N은 노드 수).
각 노드에 절대 라인 번호를 캐싱하고 노드 목록에 대해 이진 검색을 사용하면 조회 속도가 향상되지만, 노드를 수정할 때마다 모든 후속 노드를 방문하여 라인 번호 델타를 적용해야 합니다. 이는 좋지 않지만 이진 검색 아이디어는 좋습니다. 같은 효과를 얻으려면 균형 이진 트리를 활용할 수 있습니다.
이제 트리 노드를 비교하는 데 사용할 메타데이터를 결정해야 합니다. 앞서 말했듯이, 문서 내 노드 오프셋이나 절대 라인 번호를 사용하면 편집 작업의 시간 복잡도가 O(N)이 됩니다. O(log n)의 시간 복잡도를 원하면 트리의 각 노드 하위 트리와 관련된 무언가가 필요합니다. 따라서 사용자가 텍스트를 편집하면 수정된 노드의 메타데이터를 다시 계산한 다음, 루트까지 메타데이터 변경 사항을 부모 노드를 따라 전파합니다.
만약 `Node`가 네 가지 속성(`bufferIndex`, `start`, `length`, `lineStarts`)만 가진다면, 결과를 찾는 데 몇 초가 걸립니다. 더 빠르게 하려면 노드의 왼쪽 하위 트리의 텍스트 길이와 줄 바꿈 수를 저장할 수도 있습니다. 이렇게 하면 루트에서 오프셋이나 라인 번호로 검색하는 것이 효율적일 수 있습니다. 오른쪽 하위 트리의 메타데이터 저장도 동일하지만 둘 다 캐싱할 필요는 없습니다.
이제 클래스는 다음과 같습니다.
class PieceTable {
buffers: string[];
rootNode: Node;
}
class Node {
bufferIndex: number;
start: number;
length: number;
lineStarts: number[];
left_subtree_length: number;
left_subtree_lfcnt: number;
left: Node;
right: Node;
parent: Node;
}
모든 종류의 균형 이진 트리 중에서, 레드-블랙 트리를 선택했습니다. 왜냐하면 '편집'에 더 친화적이기 때문입니다.
객체 할당 줄이기
각 노드에 줄 바꿈 오프셋을 저장한다고 가정해 봅시다. 노드를 변경할 때마다 줄 바꿈 오프셋을 업데이트해야 할 수 있습니다. 예를 들어, 999개의 줄 바꿈 문자가 포함된 노드가 있고 `lineStarts` 배열이 1000개의 요소를 가지고 있다고 가정해 봅시다. 노드를 균등하게 분할하면 각각 약 500개의 요소를 가진 배열을 가진 두 개의 노드가 생성됩니다. 선형 메모리 공간을 직접 조작하는 것이 아니므로, 배열을 두 개로 분할하는 것은 포인터를 이동하는 것보다 더 비용이 많이 듭니다.
좋은 소식은 피스 테이블의 버퍼는 읽기 전용(원본 버퍼)이거나 추가 전용(변경 버퍼)이므로, 버퍼 내의 줄 바꿈 문자는 이동하지 않는다는 것입니다. `Node`는 해당 버퍼의 줄 바꿈 오프셋에 대한 두 개의 참조만 보유하면 됩니다. 적게 할수록 성능이 좋습니다. 우리의 벤치마크는 이 변경 사항을 적용함으로써 텍스트 버퍼 작업이 세 배 빨라졌음을 보여주었습니다. 하지만 실제 구현에 대해서는 나중에 더 자세히 설명하겠습니다.
class Buffer {
value: string;
lineStarts: number[];
}
class BufferPosition {
index: number; // index in Buffer.lineStarts
remainder: number;
}
class PieceTable {
buffers: Buffer[];
rootNode: Node;
}
class Node {
bufferIndex: number;
start: BufferPosition;
end: BufferPosition;
...
}
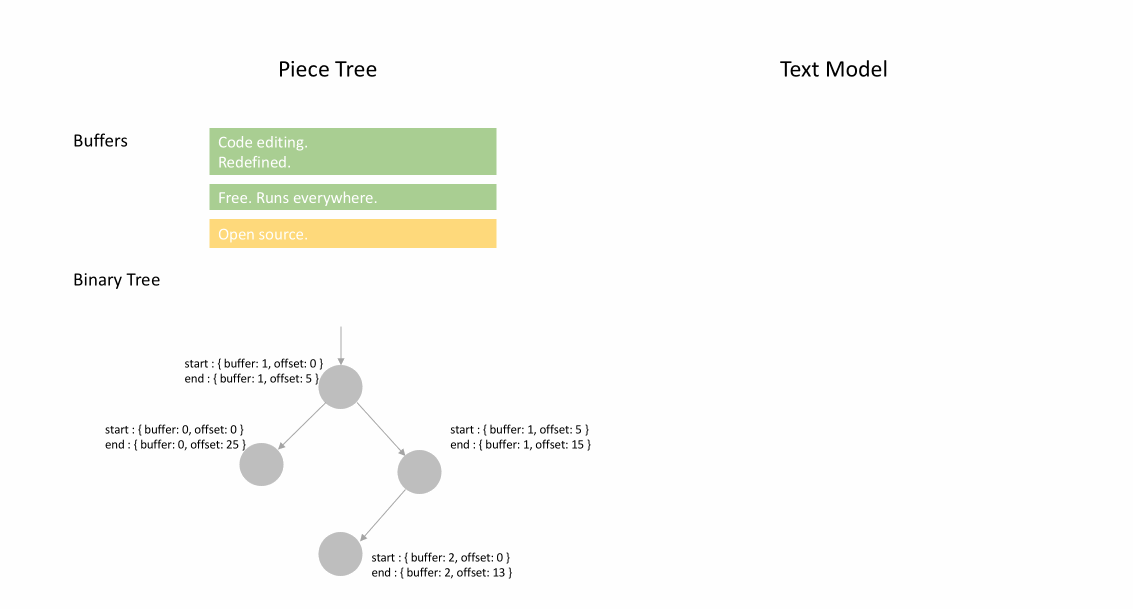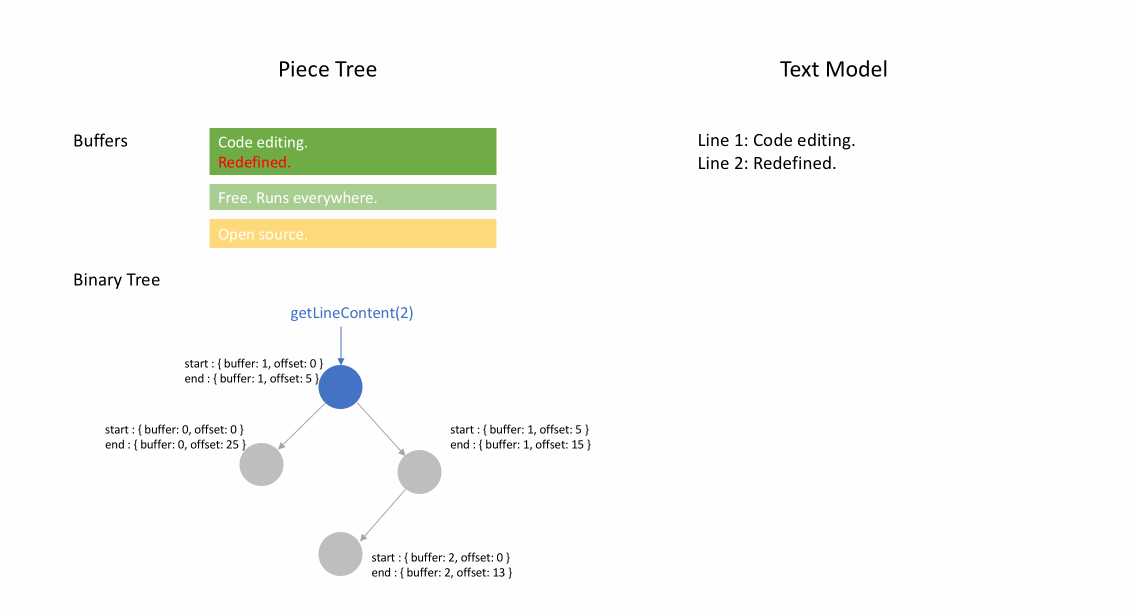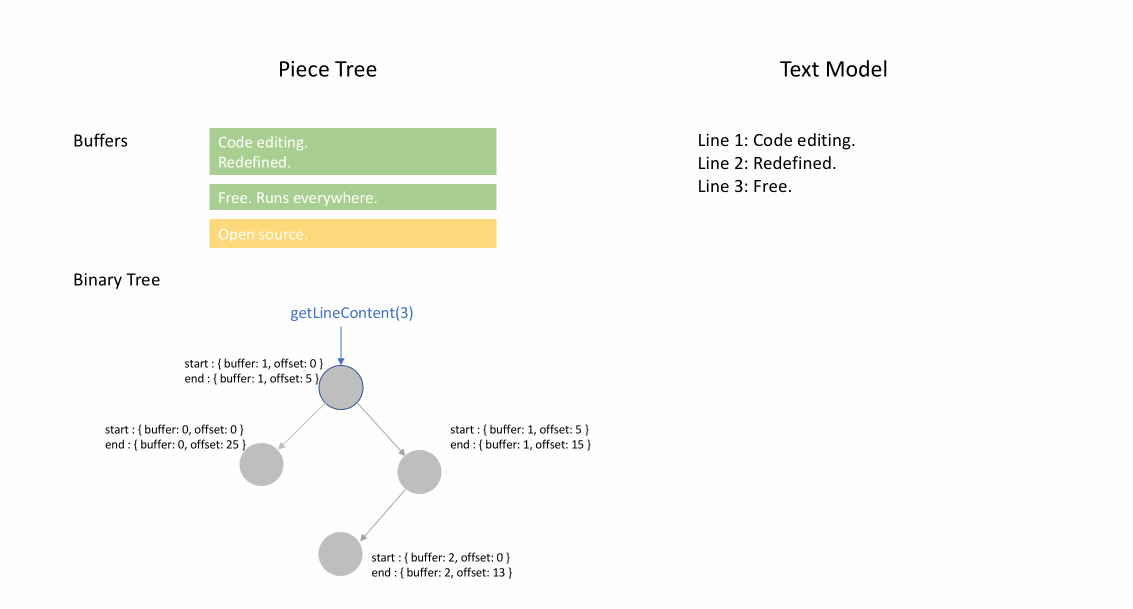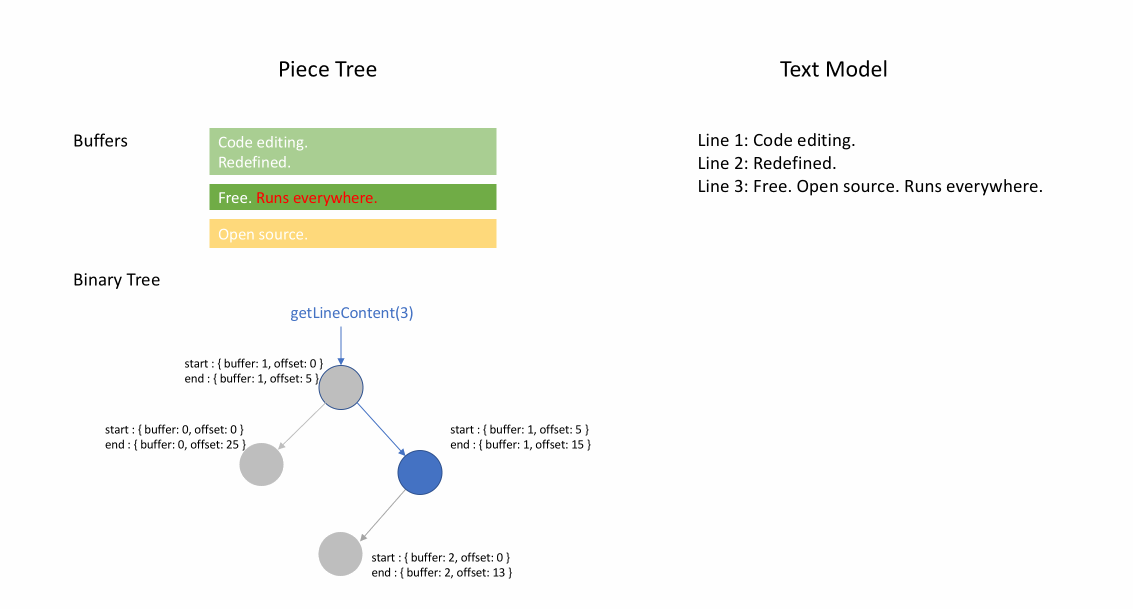
피스 트리
이 텍스트 버퍼를 "레드-블랙 트리로 최적화된 다중 버퍼 피스 테이블"이라고 부르고 싶습니다. 하지만 일일 스탠드업에서 모두가 90초로 제한되어 자신의 진행 상황을 공유해야 할 때, 이 긴 이름을 여러 번 반복하는 것은 현명하지 않을 것입니다. 그래서 저는 그것이 무엇인지 반영하는 "피스 트리"라고 부르기 시작했습니다.
이 데이터 구조에 대한 이론적 이해는 한 가지이고, 실제 성능은 또 다른 문제입니다. 사용하는 언어, 코드가 실행되는 환경, 클라이언트가 API를 호출하는 방식, 그리고 다른 요인들이 결과에 큰 영향을 미칠 수 있습니다. 벤치마크는 포괄적인 그림을 제공할 수 있으므로, 우리는 원본 라인 배열 구현과 피스 트리 구현을 대상으로 소형/중형/대형 파일에 대한 벤치마크를 실행했습니다.
준비
결과를 설명하기 위해 온라인에서 현실적인 파일을 찾았습니다.
- checker.ts - 1.46MB, 26k 라인.
- sqlite.c - 4.31MB, 128k 라인.
- 러시아어-영어 이중 언어 사전 - 14MB, 552k 라인.
그리고 몇 개의 대용량 파일을 수동으로 만들었습니다.
- 새로 열린 VS Code Insider의 Chromium 힙 스냅샷 - 54MB, 3M 라인.
- checker.ts X 128 - 184MB, 3M 라인.
1. 메모리 사용량
피스 트리의 로드 직후 메모리 사용량은 원본 파일 크기와 매우 가깝고, 이전 구현보다 훨씬 낮습니다. 첫 번째 라운드, 피스 트리의 승리입니다.
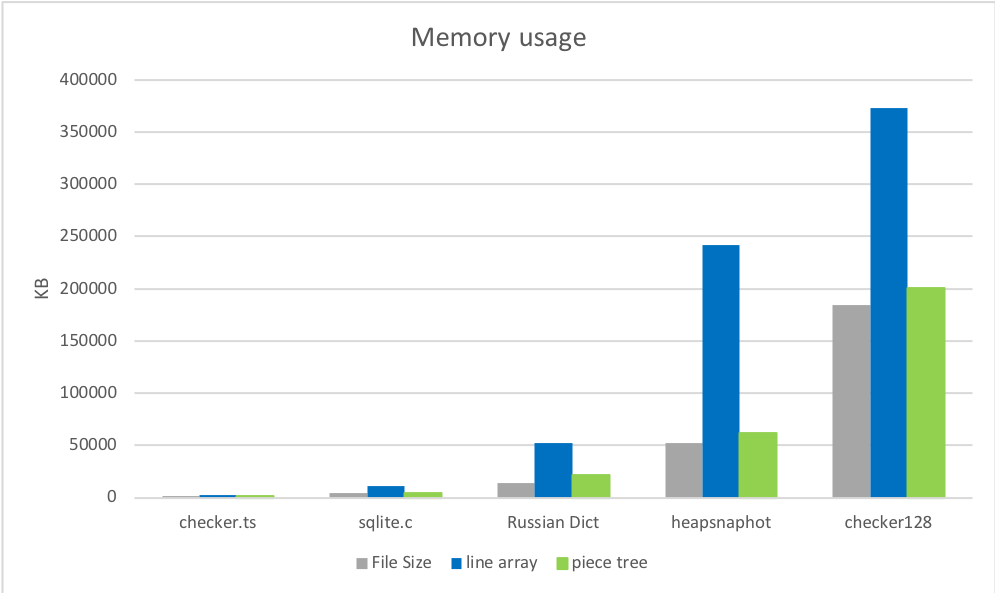
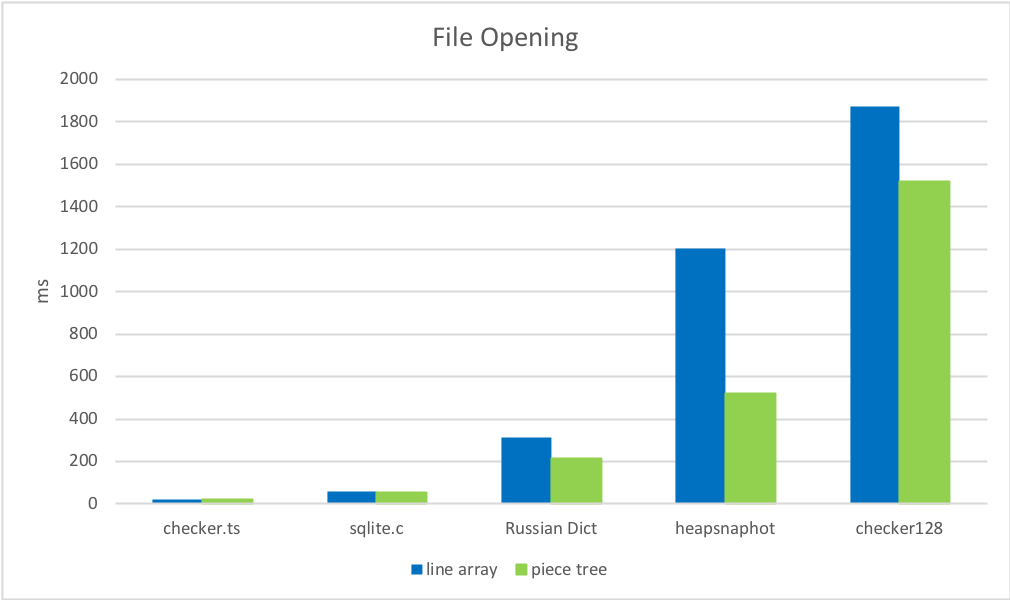
2. 파일 열기 시간
줄 바꿈 문자를 찾고 캐싱하는 것이 파일을 문자열 배열로 분할하는 것보다 훨씬 빠릅니다.
3. 편집
두 가지 워크플로우를 시뮬레이션했습니다.
- 문서의 임의 위치에서 편집.
- 순차적으로 입력.
이 두 가지 시나리오를 모방하려고 시도했습니다: 문서에 1000개의 임의 편집을 적용하거나 1000개의 순차적 삽입을 한 후, 각 텍스트 버퍼가 얼마나 걸리는지 확인합니다.
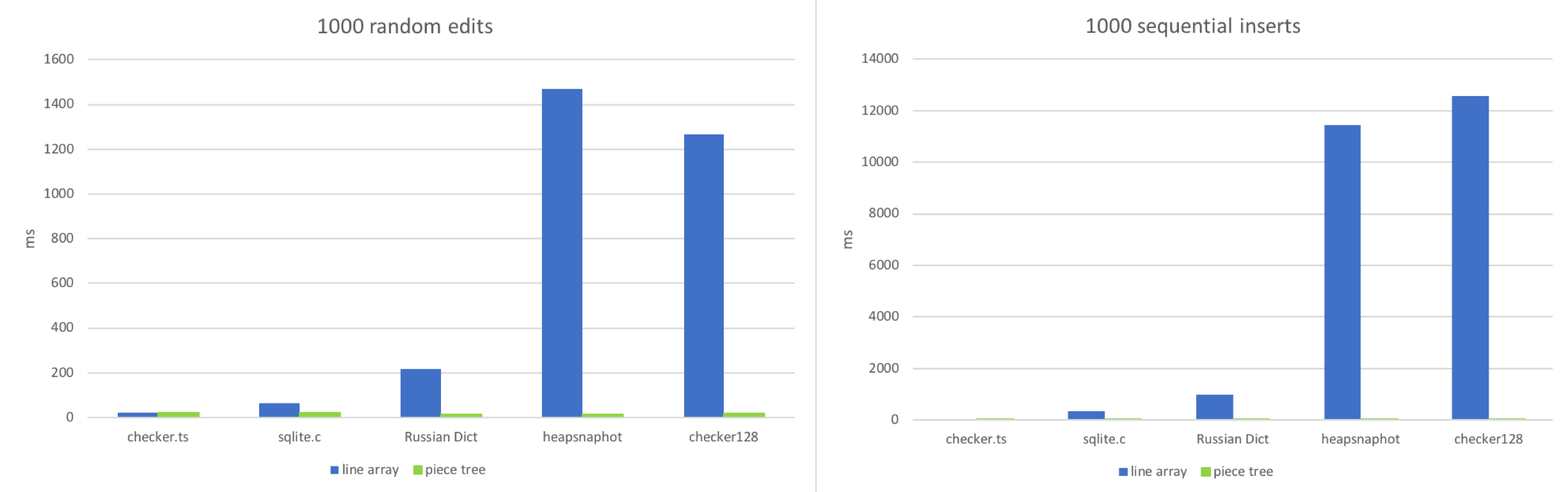
예상대로, 파일이 매우 작을 때는 라인 배열이 우세합니다. 작은 배열에서 임의 위치에 액세스하고 약 100~150자 길이의 문자열을 수정하는 것은 정말 빠릅니다. 라인 배열은 파일에 많은 라인(100k 이상)이 있을 때 성능이 저하되기 시작합니다. 대용량 파일에서의 순차적 삽입은 JavaScript 엔진이 큰 배열 크기를 조정하기 위해 많은 작업을 수행하기 때문에 이 상황을 악화시킵니다. 각 편집은 단순히 문자열 추가와 몇 가지 레드-블랙 트리 작업이므로 피스 트리는 안정적으로 작동합니다.
4. 읽기
우리의 텍스트 버퍼에서 가장 자주 사용되는 메서드는 `getLineContent`입니다. 뷰 코드, 토크나이저, 링크 감지기, 그리고 문서 콘텐츠에 의존하는 거의 모든 구성 요소에서 호출됩니다. 링크 감지기처럼 전체 파일을 탐색하는 코드도 있고, 뷰 코드처럼 순차적인 라인 창만 읽는 코드도 있습니다. 그래서 다양한 시나리오에서 이 메서드를 벤치마크하기 시작했습니다.
- 1000개의 임의 편집 후 모든 라인에 대해 `getLineContent` 호출.
- 1000개의 순차적 삽입 후 모든 라인에 대해 `getLineContent` 호출.
- 1000개의 임의 편집 후 10개의 분리된 라인 창 읽기.
- 1000개의 순차적 삽입 후 10개의 분리된 라인 창 읽기.
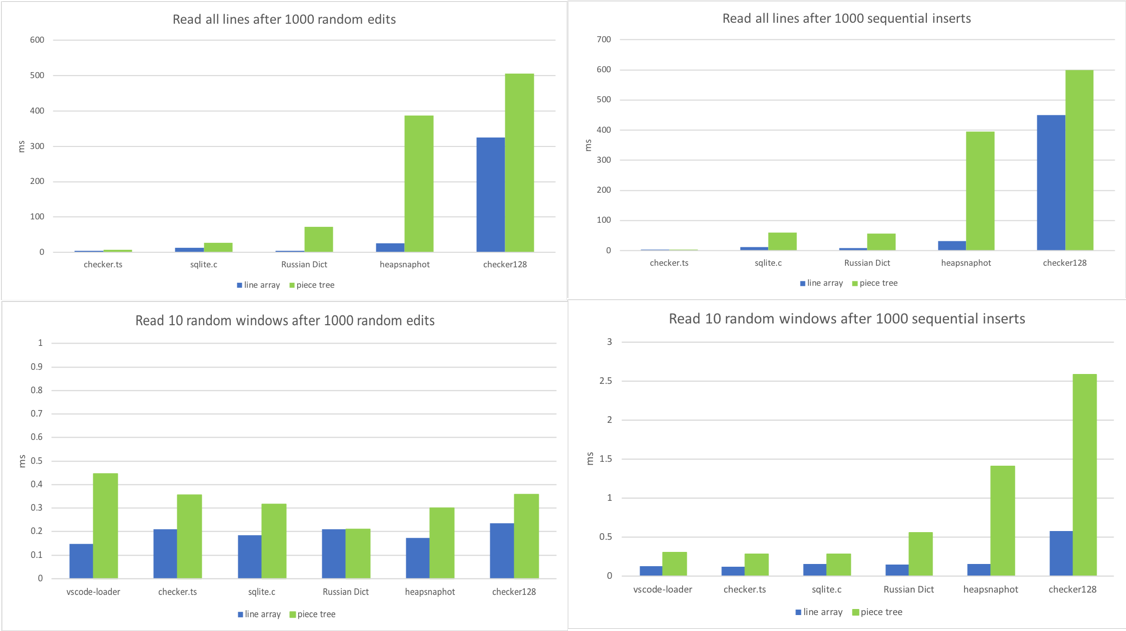
짠! 피스 트리의 아킬레스건을 발견했습니다. 1000개의 편집이 있는 대용량 파일은 수천 또는 수만 개의 노드를 생성합니다. 라인 조회가 `O(log N)` (N은 노드 수)이더라도, 이는 라인 배열이 제공하는 `O(1)`보다 훨씬 큽니다.
수천 개의 편집이 있는 경우는 상대적으로 드뭅니다. 대용량 파일에서 자주 발생하는 문자열 시퀀스를 대체한 후 그럴 수 있습니다. 또한, 각 `getLineContent` 호출은 마이크로초 단위이며, 현재로서는 크게 걱정할 만한 문제는 아닙니다. 대부분의 `getLineContent` 호출은 뷰 렌더링 및 토큰화에서 발생하며, 라인 콘텐츠의 후처리 과정이 훨씬 더 시간을 많이 소모합니다. 뷰포트의 DOM 구성 및 렌더링 또는 토큰화는 일반적으로 수십 밀리초가 소요되며, 그 중 `getLineContent`는 1% 미만을 차지합니다. 그럼에도 불구하고, 노드 수가 많다는 등의 특정 조건이 충족되면 버퍼와 노드를 다시 생성하는 정규화 단계를 구현하는 것을 고려하고 있습니다.
결론 및 주의사항
피스 트리는 라인 기반 조회(예상대로)를 제외한 대부분의 시나리오에서 라인 배열보다 우수한 성능을 보입니다.
배운 점
- 이 재구현을 통해 배운 가장 중요한 교훈은 **항상 실제 프로파일링을 수행하라**는 것입니다. 메서드에 대한 나의 가정과 실제 상황이 일치하지 않는 경우가 많았습니다. 예를 들어, 피스 트리 구현을 시작할 때 세 가지 원자적 작업(insert, delete, search)을 최적화하는 데 집중했습니다. 하지만 VS Code에 통합했을 때, 그러한 최적화는 아무런 의미가 없었습니다. 가장 자주 사용된 메서드는 `getLineContent`였습니다.
- `CRLF` 또는 혼합 줄 바꿈 시퀀스 처리는 프로그래머에게 악몽입니다. 각 수정에 대해 캐리지 리턴/라인 피드(CRLF) 시퀀스를 분할하는지, 또는 새 CRLF 시퀀스를 생성하는지 확인해야 합니다. 트리 맥락에서 가능한 모든 경우를 처리하는 데는 올바르고 빠른 솔루션을 찾기까지 몇 번의 시도가 필요했습니다.
- GC는 CPU 시간을 쉽게 잡아먹을 수 있습니다. 이전 텍스트 모델은 버퍼가 배열에 저장되어 있다고 가정했고, 때로는 필요하지 않은 경우에도 `getLineContent`를 자주 사용했습니다. 예를 들어, 라인의 첫 번째 문자의 문자 코드를 알고 싶을 때 `getLineContent`를 먼저 사용하고 `charCodeAt`을 사용했습니다. 피스 트리에서는 `getLineContent`가 부분 문자열을 생성하고 문자 코드를 확인한 후 라인 부분 문자열이 즉시 버려집니다. 이는 낭비이며, 더 적합한 메서드를 채택하기 위해 노력하고 있습니다.
왜 네이티브가 아닌가?
처음에 이 질문으로 돌아오겠다고 약속했습니다.
요약: 시도했지만 우리에게는 효과가 없었습니다.
C++로 텍스트 버퍼 구현을 만들고 네이티브 노드 모듈 바인딩을 사용하여 VS Code에 통합했습니다. 텍스트 버퍼는 VS Code에서 인기 있는 구성 요소이므로 텍스트 버퍼에 대한 많은 호출이 발생했습니다. 호출자와 구현 모두 JavaScript로 작성되었을 때, V8은 이러한 호출 중 많은 부분을 인라인할 수 있었습니다. 네이티브 텍스트 버퍼의 경우, **JavaScript <=> C++** 왕복이 발생하고, 왕복 횟수를 고려하면 모든 것을 느리게 만들었습니다.
예를 들어, VS Code의 **라인 주석 토글** 명령은 선택된 모든 라인을 반복하고 각 라인을 하나씩 분석하여 구현됩니다. 이 로직은 JavaScript로 작성되었으며, 각 라인에 대해 `TextBuffer.getLineContent`를 호출합니다. 각 호출마다 C++/JavaScript 경계를 넘어야 하고, 모든 코드가 기반으로 하는 API를 존중하기 위해 JavaScript `string`을 반환해야 합니다.
우리의 선택은 간단합니다. C++에서는 `getLineContent`를 호출할 때마다 새 JavaScript `string`을 할당하여 실제 문자열 바이트를 복사하거나, V8의 `SlicedString` 또는 `ConstString` 타입을 활용할 수 있습니다. 그러나 V8 문자열 타입을 사용하려면 기본 저장소가 V8 문자열을 사용해야 합니다. 안타깝게도 V8 문자열은 멀티스레드 안전하지 않습니다.
텍스트 버퍼 API를 변경하거나, JavaScript/C++ 경계 비용을 피하기 위해 더 많은 코드를 C++로 이동하는 등의 방법으로 이를 극복하려고 시도할 수 있었습니다. 그러나 우리는 동시에 두 가지 일을 하고 있음을 깨달았습니다. 라인 배열과 다른 데이터 구조를 사용하여 텍스트 버퍼를 작성하고 있었고, JavaScript 대신 C++로 작성하고 있었습니다. 따라서 보상받을지 확신할 수 없는 것에 반년을 소비하는 대신, 텍스트 버퍼의 런타임을 JavaScript에 유지하고 데이터 구조 및 관련 알고리즘만 변경하기로 결정했습니다. 우리의 의견으로는 이것이 올바른 결정이었습니다.
향후 작업
최적화가 필요한 몇 가지 경우가 아직 남아 있습니다. 예를 들어, **찾기** 명령은 현재 라인별로 실행되지만 그렇게 해서는 안 됩니다. 라인 부분 문자열만 필요한 경우 불필요한 `getLineContent` 호출을 피할 수도 있습니다. 이러한 추가 최적화는 점진적으로 릴리스할 예정입니다. 이러한 추가 최적화 없이도 새로운 텍스트 버퍼 구현은 이전보다 더 나은 사용자 경험을 제공하며, 최신 안정 버전 VS Code에서 기본값으로 사용되고 있습니다.
행복한 코딩 되세요!
Peng Lyu, VS Code 팀원 @njukidreborn