VS Code에서 데이터 과학 튜토리얼
이 튜토리얼은 Visual Studio Code와 Microsoft Python 확장을 일반적인 데이터 과학 라이브러리와 함께 사용하여 기본적인 데이터 과학 시나리오를 탐색하는 방법을 보여줍니다. 특히 타이타닉 승객 데이터를 사용하여 데이터 과학 환경을 설정하고, 데이터를 가져오고 정리하고, 타이타닉 생존 예측을 위한 머신러닝 모델을 만들고, 생성된 모델의 정확도를 평가하는 방법을 배웁니다.
전제 조건
이 튜토리얼을 완료하려면 다음 설치가 필요합니다. 아직 설치하지 않았다면 설치하십시오.
-
Visual Studio Marketplace에서 VS Code용 Python 확장 및 VS Code용 Jupyter 확장. 확장을 설치하는 방법에 대한 자세한 내용은 확장 마켓플레이스를 참조하십시오. 두 확장 모두 Microsoft에서 게시했습니다.
-
참고: 이미 전체 Anaconda 배포판이 설치되어 있다면 Miniconda를 설치할 필요가 없습니다. 또는 Anaconda 또는 Miniconda를 사용하지 않으려면 Python 가상 환경을 만들고 pip를 사용하여 튜토리얼에 필요한 패키지를 설치할 수 있습니다. 이 경우 다음 패키지를 설치해야 합니다: pandas, jupyter, seaborn, scikit-learn, keras, tensorflow.
데이터 과학 환경 설정
Visual Studio Code와 Python 확장은 데이터 과학 시나리오에 훌륭한 편집기를 제공합니다. Anaconda와 함께 Jupyter 노트북에 대한 네이티브 지원을 통해 쉽게 시작할 수 있습니다. 이 섹션에서는 튜토리얼을 위한 작업 영역을 만들고, 튜토리얼에 필요한 데이터 과학 모듈로 Anaconda 환경을 만들고, 머신러닝 모델을 만드는 데 사용할 Jupyter 노트북을 만듭니다.
-
먼저 데이터 과학 튜토리얼을 위한 Anaconda 환경을 만듭니다. Anaconda 명령 프롬프트를 열고
conda create -n myenv python=3.10 pandas jupyter seaborn scikit-learn keras tensorflow를 실행하여 **myenv**라는 환경을 만듭니다. Anaconda 환경을 만들고 관리하는 방법에 대한 자세한 내용은 Anaconda 설명서를 참조하십시오. -
다음으로, 튜토리얼을 위한 VS Code 작업 영역으로 사용할 편리한 위치에 폴더를 만들고
hello_ds라고 이름을 지정합니다. -
VS Code를 실행하고 **파일** > **폴더 열기** 명령을 사용하여 프로젝트 폴더를 VS Code에서 엽니다. 폴더를 직접 만들었으므로 안전하게 열 수 있습니다.
-
VS Code가 시작되면 튜토리얼에 사용할 Jupyter 노트북을 만듭니다. 명령 팔레트(⇧⌘P (Windows, Linux Ctrl+Shift+P))를 열고 **만들기: 새 Jupyter 노트북**을 선택합니다.

참고: 또는 VS Code 파일 탐색기에서 새 파일 아이콘을 사용하여
hello.ipynb라는 이름의 노트북 파일을 만들 수도 있습니다. -
**파일** > **다른 이름으로 저장...**을 사용하여 파일을
hello.ipynb로 저장합니다. -
파일이 생성되면 노트북 편집기에서 열린 Jupyter 노트북이 표시되어야 합니다. 네이티브 Jupyter 노트북 지원에 대한 자세한 내용은 Jupyter 노트북 항목을 읽어볼 수 있습니다.
-
이제 노트북 오른쪽 상단의 **커널 선택**을 선택합니다.

-
커널을 실행할 위에서 만든 Python 환경을 선택합니다.
-
VS Code 통합 터미널에서 환경을 관리하려면 (⌃` (Windows, Linux Ctrl+`))를 사용하여 엽니다. 환경이 활성화되지 않은 경우 터미널에서처럼 활성화할 수 있습니다(
conda activate myenv).
데이터 준비
이 튜토리얼에서는 타이타닉 데이터셋을 OpenML.org에서 사용하며, 이 데이터셋은 Vanderbilt University의 Biostatistics 학과에서 https://hbiostat.org/data에서 얻은 것입니다. 타이타닉 데이터는 타이타닉 승객의 생존 정보와 나이, 티켓 등급과 같은 승객에 대한 특징을 제공합니다. 이 데이터를 사용하여 튜토리얼에서는 주어진 승객이 타이타닉 침몰에서 생존했을지 여부를 예측하는 모델을 수립합니다. 이 섹션에서는 Jupyter 노트북에서 데이터를 로드하고 조작하는 방법을 보여줍니다.
-
먼저 hbiostat.org에서 타이타닉 데이터를 CSV 파일로 다운로드하고 (오른쪽 상단에 다운로드 링크 있음) 이전 섹션에서 만든
hello_ds폴더에titanic3.csv라는 이름으로 저장합니다. -
아직 VS Code에서 파일을 열지 않았다면 **파일** > **폴더 열기**로 이동하여
hello_ds폴더와 Jupyter 노트북(hello.ipynb)을 엽니다. -
Jupyter 노트북 내에서 데이터를 조작하는 데 사용되는 두 개의 일반적인 라이브러리인 pandas와 numpy 라이브러리를 가져와 타이타닉 데이터를 pandas DataFrame으로 로드하는 것부터 시작합니다. 이를 위해 아래 코드를 노트북의 첫 번째 셀에 복사합니다. VS Code에서 Jupyter 노트북으로 작업하는 방법에 대한 자세한 내용은 Jupyter 노트북 작업 문서를 참조하십시오.
import pandas as pd import numpy as np data = pd.read_csv('titanic3.csv') -
이제 실행 아이콘 또는 Shift+Enter 바로 가기를 사용하여 셀을 실행합니다.

-
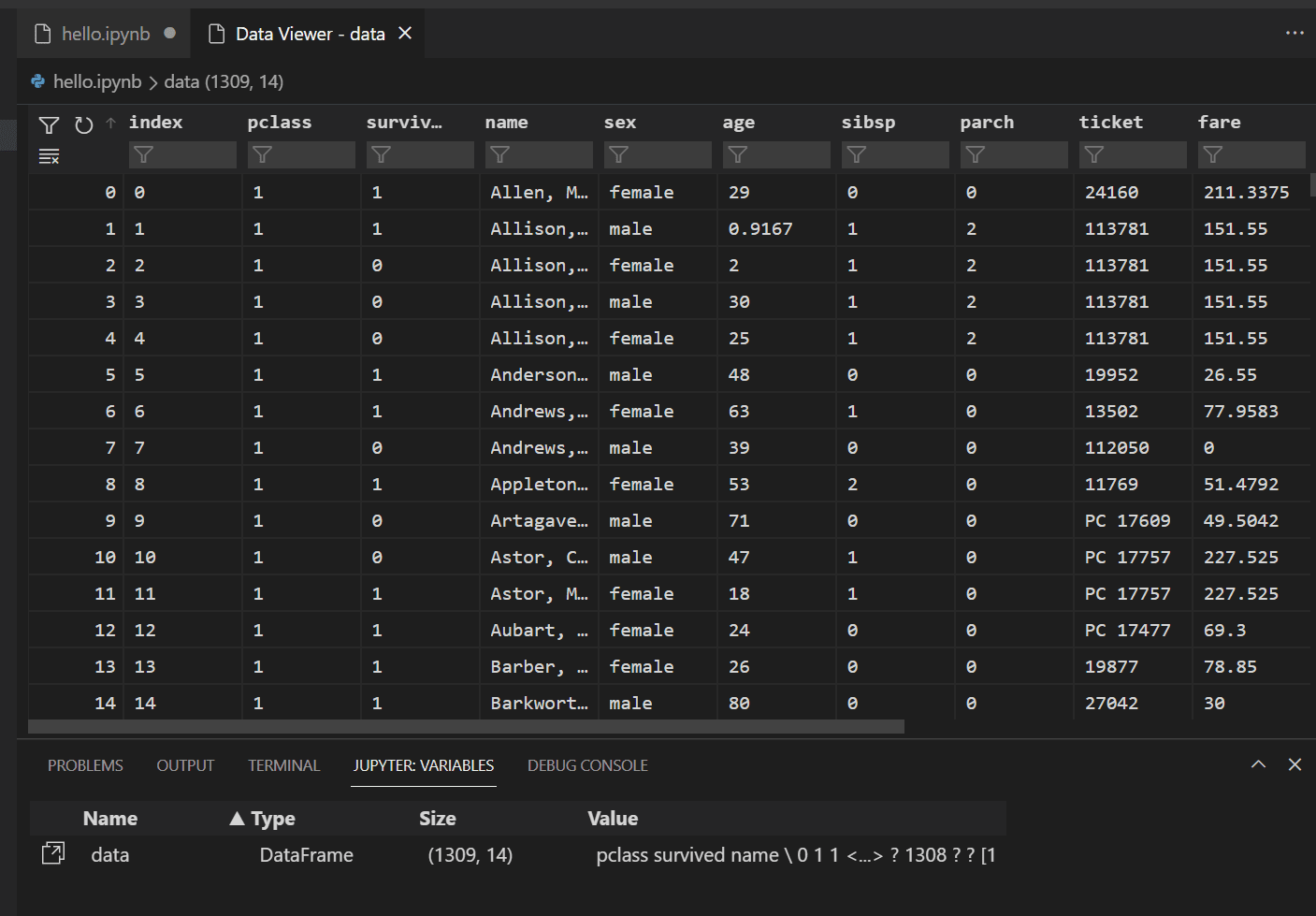
셀 실행이 완료된 후 변수 탐색기 및 데이터 뷰어를 사용하여 로드된 데이터를 볼 수 있습니다. 먼저 노트북 상단 도구 모음에서 **변수** 아이콘을 선택합니다.
-
VS Code 하단에 **JUPYTER: VARIABLES** 창이 열립니다. 여기에는 실행 중인 커널에서 지금까지 정의된 변수 목록이 포함되어 있습니다.
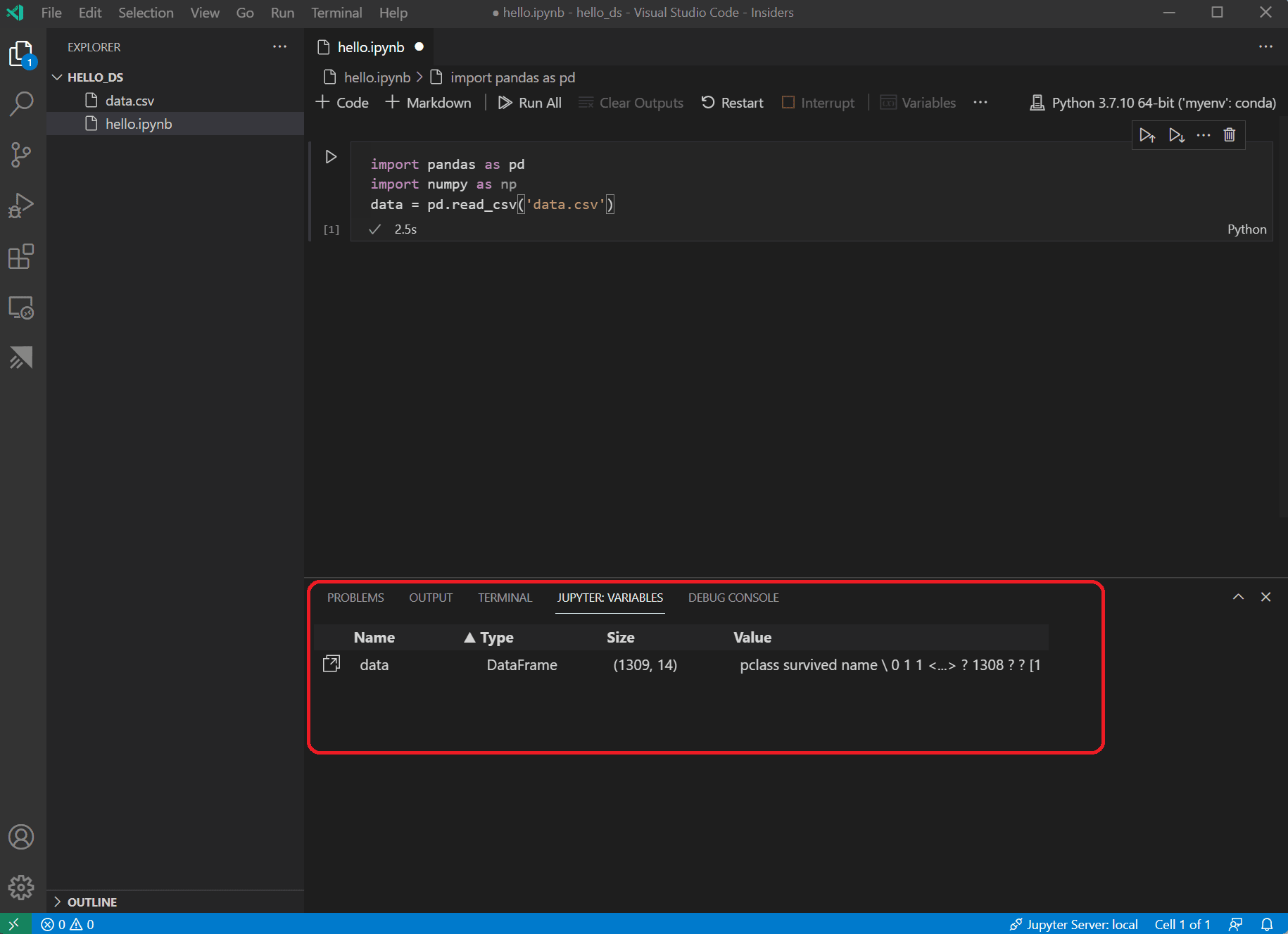
-
이전에 로드된 Pandas DataFrame의 데이터를 보려면
data변수 왼쪽에 있는 데이터 뷰어 아이콘을 선택합니다.
-
데이터 뷰어를 사용하여 데이터를 보고, 정렬하고, 필터링합니다. 데이터를 검토한 후에는 다른 변수 간의 관계를 시각화하는 데 도움이 되도록 데이터의 일부를 그래프로 그리는 것이 유용할 수 있습니다.
대안으로, Data Wrangler와 같은 다른 확장에서 제공하는 데이터 보기 환경을 사용할 수도 있습니다. Data Wrangler 확장은 데이터에 대한 통찰력을 보여주는 풍부한 사용자 인터페이스를 제공하고 데이터 프로파일링, 품질 확인, 변환 등을 수행하는 데 도움이 됩니다. 문서에서 Data Wrangler 확장에 대해 자세히 알아보십시오.
-
데이터를 그래프로 그리기 전에 데이터에 문제가 없는지 확인해야 합니다. 타이타닉 CSV 파일을 보면, 누락된 데이터가 있는 셀을 식별하기 위해 물음표("?")가 사용되었다는 것을 알게 될 것입니다.
Pandas는 이 값을 DataFrame으로 읽을 수 있지만, **age**와 같은 열의 결과는 숫자 데이터 유형 대신 **object**로 설정되며, 이는 그래프 작성에 문제가 됩니다.
이 문제는 물음표를 pandas가 이해할 수 있는 누락된 값으로 대체하여 수정할 수 있습니다. 노트북의 다음 셀에 다음 코드를 추가하여 **age** 및 **fare** 열의 물음표를 numpy NaN 값으로 대체합니다. 값을 대체한 후 열의 데이터 유형을 업데이트해야 한다는 점에 유의하십시오.
팁: 새 셀을 추가하려면 기존 셀의 왼쪽 하단에 있는 셀 삽입 아이콘을 사용할 수 있습니다. 또는 Esc를 사용하여 명령 모드로 들어간 다음 B 키를 누를 수도 있습니다.
data.replace('?', np.nan, inplace= True) data = data.astype({"age": np.float64, "fare": np.float64})참고: 열에 사용된 데이터 유형을 확인해야 하는 경우 DataFrame dtypes 속성을 사용할 수 있습니다.
-
이제 데이터가 좋은 상태이므로 seaborn과 matplotlib을 사용하여 데이터셋의 특정 열이 생존율과 어떻게 관련되는지 볼 수 있습니다. 다음 코드를 노트북의 다음 셀에 추가하고 실행하여 생성된 플롯을 봅니다.
import seaborn as sns import matplotlib.pyplot as plt fig, axs = plt.subplots(ncols=5, figsize=(30,5)) sns.violinplot(x="survived", y="age", hue="sex", data=data, ax=axs[0]) sns.pointplot(x="sibsp", y="survived", hue="sex", data=data, ax=axs[1]) sns.pointplot(x="parch", y="survived", hue="sex", data=data, ax=axs[2]) sns.pointplot(x="pclass", y="survived", hue="sex", data=data, ax=axs[3]) sns.violinplot(x="survived", y="fare", hue="sex", data=data, ax=axs[4])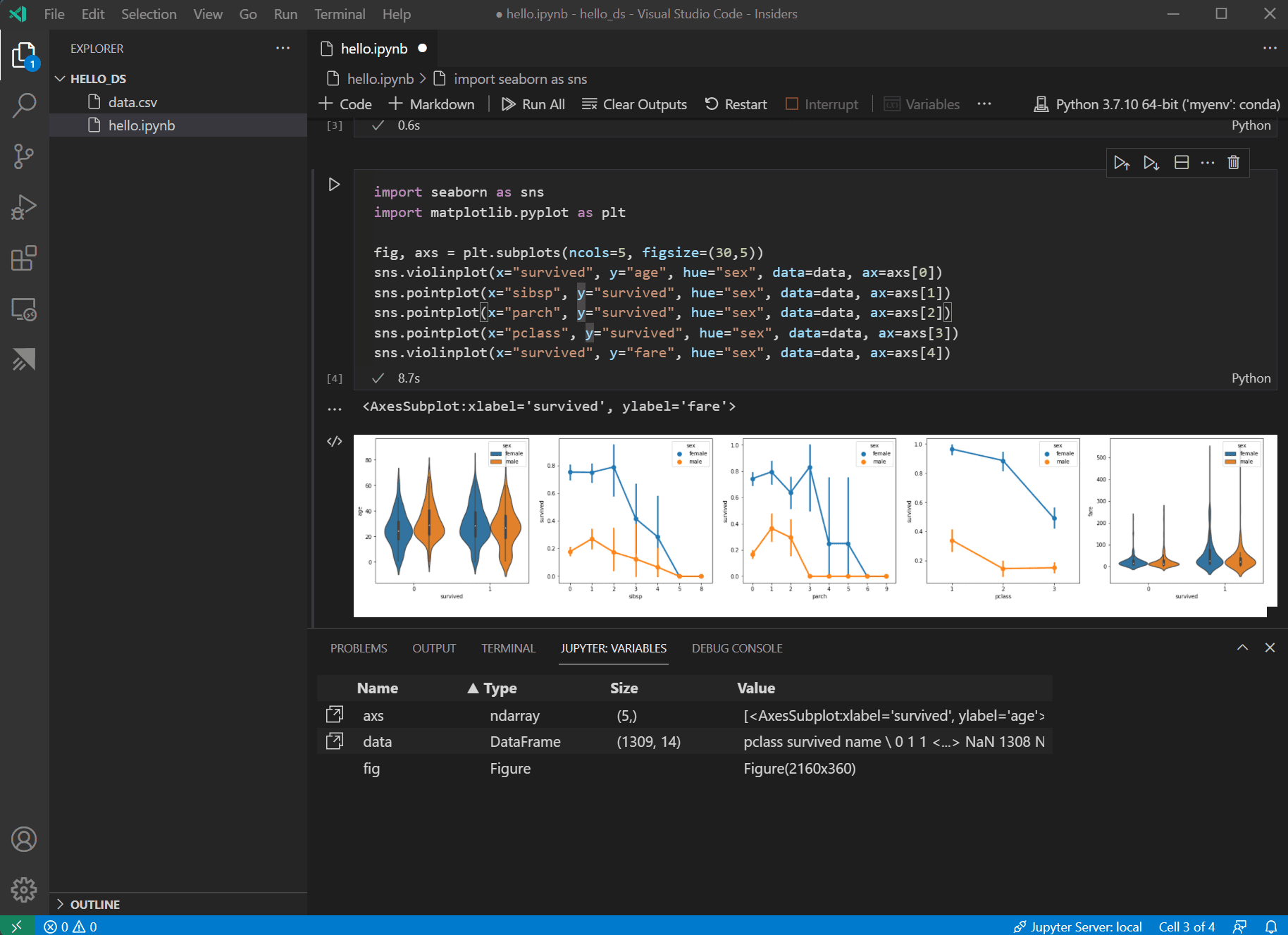
팁: 그래프를 빠르게 복사하려면 그래프 오른쪽 상단에 마우스를 올리고 나타나는 **클립보드로 복사** 버튼을 클릭할 수 있습니다. **이미지 확장** 버튼을 클릭하여 그래프의 세부 정보를 더 잘 볼 수도 있습니다.

-
이러한 그래프는 생존과 데이터의 입력 변수 간의 일부 관계를 보는 데 도움이 되지만, **pandas**를 사용하여 상관 관계를 계산할 수도 있습니다. 이를 위해서는 사용되는 모든 변수가 숫자여야 하며 현재 성별은 문자열로 저장되어 있습니다. 이러한 문자열 값을 정수로 변환하려면 다음 코드를 추가하고 실행합니다.
data.replace({'male': 1, 'female': 0}, inplace=True) -
이제 모든 입력 변수 간의 상관 관계를 분석하여 머신러닝 모델에 가장 적합한 입력이 될 특성을 식별할 수 있습니다. 값이 1에 가까울수록 해당 값과 결과 간의 상관 관계가 높습니다. 다음 코드를 사용하여 모든 변수와 생존 간의 관계를 상관시킵니다.
data.corr(numeric_only=True).abs()[["survived"]]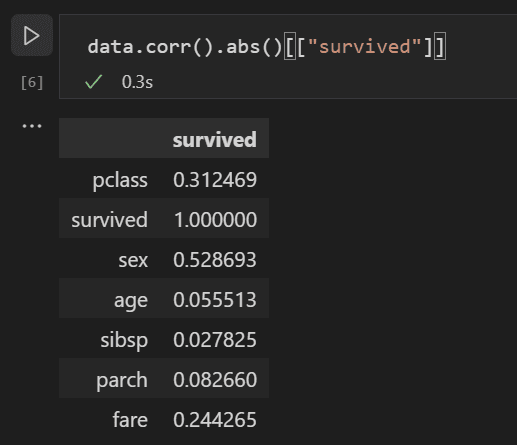
-
상관 관계 결과를 보면 성별과 같은 일부 변수는 생존율에 상당히 높은 상관 관계를 갖는 반면, 친척(sibsp = 형제자매 또는 배우자, parch = 부모 또는 자녀)과 같은 다른 변수는 상관 관계가 거의 없는 것으로 보입니다.
sibsp와 parch가 생존율에 미치는 영향과 관련이 있다고 가정하고 "relatives"라는 새 열로 그룹화하여 그 조합이 생존율에 더 높은 상관 관계를 갖는지 확인해 보겠습니다. 이를 위해 특정 승객에 대해 sibsp와 parch의 수가 0보다 큰지 확인하고, 그렇다면 탑승한 친척이 있다고 말할 수 있습니다.
다음 코드를 사용하여 데이터셋에
relatives라는 새 변수와 열을 만들고 상관 관계를 다시 확인합니다.data['relatives'] = data.apply (lambda row: int((row['sibsp'] + row['parch']) > 0), axis=1) data.corr(numeric_only=True).abs()[["survived"]]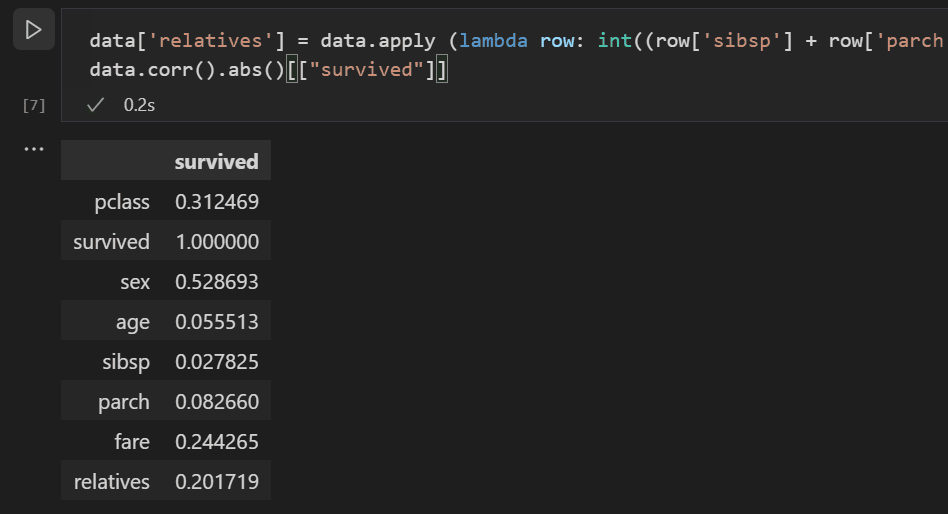
-
사람이 친척이 있는지 여부의 관점에서 볼 때, 몇 명의 친척이 있는지에 비해 생존율과의 상관 관계가 더 높다는 것을 실제로 알 수 있습니다. 이 정보를 바탕으로 데이터셋에서 낮은 값의 sibsp 및 parch 열과 **NaN** 값이 있는 행을 삭제하여 모델 학습에 사용할 수 있는 데이터셋을 얻을 수 있습니다.
data = data[['sex', 'pclass','age','relatives','fare','survived']].dropna()참고: 나이는 직접적인 상관 관계가 낮았지만, 다른 입력과 함께 여전히 상관 관계가 있을 수 있다고 생각되므로 유지되었습니다.
모델 학습 및 평가
데이터셋이 준비되었으므로 모델 만들기를 시작할 수 있습니다. 이 섹션에서는 scikit-learn 라이브러리(유용한 도우미 함수 제공)를 사용하여 데이터셋의 전처리, 타이타닉 생존율을 결정하는 분류 모델 학습, 그리고 해당 모델을 테스트 데이터에 사용하여 정확도를 결정합니다.
-
모델 학습의 일반적인 첫 번째 단계는 데이터셋을 학습 및 유효성 검사 데이터로 분할하는 것입니다. 이를 통해 데이터의 일부를 사용하여 모델을 학습하고 데이터의 일부를 사용하여 모델을 테스트할 수 있습니다. 모델을 학습하기 위해 모든 데이터를 사용하면 모델이 아직 보지 못한 데이터에 대해 얼마나 잘 수행될지 추정할 방법이 없을 것입니다. scikit-learn 라이브러리의 장점은 데이터셋을 학습 및 테스트 데이터로 분할하는 특정 메서드를 제공한다는 것입니다.
노트북에 다음 코드를 포함하는 셀을 추가하고 실행하여 데이터를 분할합니다.
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data[['sex','pclass','age','relatives','fare']], data.survived, test_size=0.2, random_state=0) -
다음으로, 모든 특징이 동일하게 취급되도록 입력을 정규화합니다. 예를 들어, 데이터셋에서 나이의 값은 ~0-100 범위이지만 성별은 1 또는 0에 불과합니다. 모든 변수를 정규화하면 값 범위가 모두 동일한지 확인할 수 있습니다. 새 코드 셀에 다음 코드를 사용하여 입력 값을 스케일링합니다.
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(x_train) X_test = sc.transform(x_test) -
데이터를 모델링하기 위해 선택할 수 있는 다양한 머신러닝 알고리즘이 있습니다. scikit-learn 라이브러리는 그 중 많은 것에 대한 지원과 시나리오에 적합한 것을 선택하는 데 도움이 되는 차트도 제공합니다. 여기서는 분류 문제에 대한 일반적인 알고리즘인 Naïve Bayes 알고리즘을 사용합니다. 다음 코드를 포함하는 셀을 추가하여 알고리즘을 만들고 학습합니다.
from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X_train, y_train) -
학습된 모델을 사용하여 학습에서 보류된 테스트 데이터 세트에 대해 테스트할 수 있습니다. 다음 코드를 추가하고 실행하여 테스트 데이터의 결과를 예측하고 모델의 정확도를 계산합니다.
from sklearn import metrics predict_test = model.predict(X_test) print(metrics.accuracy_score(y_test, predict_test))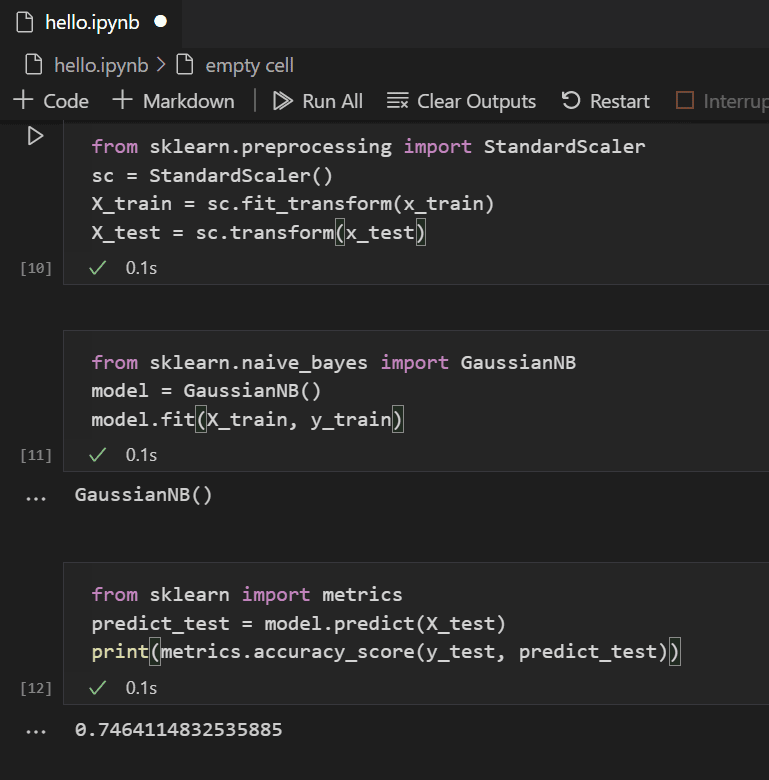
테스트 데이터 결과를 보면 학습된 알고리즘이 생존율 추정에서 약 75%의 성공률을 보인다는 것을 알 수 있습니다.
(선택 사항) 신경망 사용
신경망은 가중치와 활성화 함수를 사용하여 인간의 뉴런 측면을 모델링하여 제공된 입력을 기반으로 결과를 결정하는 모델입니다. 이전에 살펴본 머신러닝 알고리즘과 달리 신경망은 딥러닝의 한 형태로, 문제 세트에 대한 이상적인 알고리즘을 미리 알 필요가 없습니다. 다양한 시나리오에 사용할 수 있으며 분류도 그 중 하나입니다. 이 섹션에서는 Keras 라이브러리를 TensorFlow와 함께 사용하여 신경망을 구성하고 타이타닉 데이터셋을 어떻게 처리하는지 살펴봅니다.
-
첫 번째 단계는 필요한 라이브러리를 가져오고 모델을 만드는 것입니다. 이 경우 순차적으로 피드되는 여러 계층이 있는 계층 신경망인 Sequential 신경망을 사용합니다.
from keras.models import Sequential from keras.layers import Dense model = Sequential() -
모델을 정의한 후 다음 단계는 신경망의 계층을 추가하는 것입니다. 지금은 간단하게 세 개의 계층만 사용하겠습니다. 다음 코드를 추가하여 신경망의 계층을 만듭니다.
model.add(Dense(5, kernel_initializer = 'uniform', activation = 'relu', input_dim = 5)) model.add(Dense(5, kernel_initializer = 'uniform', activation = 'relu')) model.add(Dense(1, kernel_initializer = 'uniform', activation = 'sigmoid'))- 첫 번째 계층은 다섯 개의 입력(성별, pclass, 나이, 친척, 요금)이 있으므로 5차원으로 설정됩니다.
- 마지막 계층은 승객이 생존할지 여부를 나타내는 1차원 출력을 원하므로 1로 출력해야 합니다.
- 가운데 계층은 단순성을 위해 5로 유지되었지만, 그 값은 다를 수 있었습니다.
ReLU(Rectified Linear Unit) 활성화 함수는 처음 두 계층에 대한 좋은 일반 활성화 함수로 사용되고, 마지막 계층에는 승객 생존 확률이라는 원하는 출력(승객이 생존할지 여부)이 0-1 범위로 스케일링되어야 하므로 시그모이드 활성화 함수가 필요합니다.
이 코드를 사용하여 구축한 모델의 요약을 볼 수도 있습니다.
model.summary()
-
모델이 생성되면 컴파일해야 합니다. 이 과정의 일부로 어떤 유형의 옵티마이저가 사용되고, 손실이 어떻게 계산되며, 어떤 지표가 최적화되어야 하는지 정의해야 합니다. 다음 코드를 추가하여 모델을 빌드하고 학습합니다. 학습 후 정확도는 ~61%입니다.
참고: 이 단계는 컴퓨터에 따라 몇 초에서 몇 분까지 걸릴 수 있습니다.
model.compile(optimizer="adam", loss='binary_crossentropy', metrics=['accuracy']) model.fit(X_train, y_train, batch_size=32, epochs=50)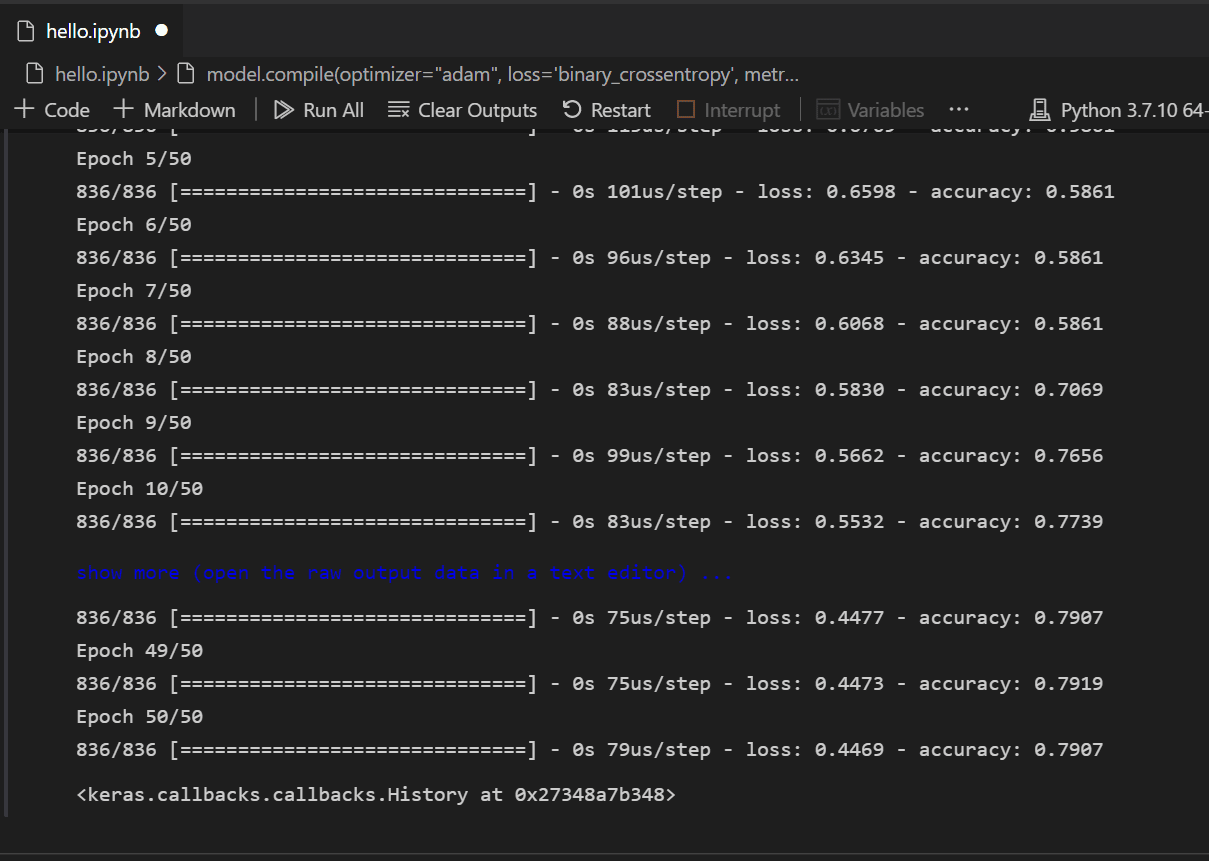
-
이제 모델이 빌드되고 학습되었으므로 테스트 데이터에 대해 어떻게 작동하는지 확인할 수 있습니다.
y_pred = np.rint(model.predict(X_test).flatten()) print(metrics.accuracy_score(y_test, y_pred))
학습과 유사하게, 이제 승객 생존 예측에서 79%의 정확도를 얻을 수 있습니다. 이 간단한 신경망을 사용하면 이전에 시도한 Naive Bayes Classifier의 75% 정확도보다 결과가 좋습니다.
다음 단계
Visual Studio Code에서 머신러닝을 수행하는 기본 사항을 익혔으니, 다음은 확인해 볼 만한 다른 Microsoft 리소스 및 튜토리얼입니다.
- 데이터 과학 프로필 템플릿 - 확장, 설정 및 스니펫이 큐레이션된 프로필을 새로 만듭니다.
- Visual Studio Code에서 Jupyter 노트북 작업에 대해 자세히 알아보기 (비디오).
- Azure의 성능을 활용하여 모델을 배포하고 최적화하려면 VS Code용 Azure Machine Learning 시작하기를 참조하십시오.
- 탐색할 더 많은 데이터는 Azure Open Data Sets에서 찾을 수 있습니다.