VS Code의 Data Wrangler 빠른 시작 가이드
Data Wrangler는 VS Code 및 VS Code Jupyter Notebook에 통합된 코드 중심의 데이터 보기 및 정리 도구입니다. 데이터를 보고 분석할 수 있는 풍부한 사용자 인터페이스를 제공하며, 통찰력 있는 열 통계 및 시각화를 보여주고 데이터를 정리하고 변환할 때 Pandas 코드를 자동으로 생성합니다.
다음은 노트북에서 Data Wrangler를 열어 내장된 작업을 사용하여 데이터를 분석하고 정리하는 예시입니다. 그런 다음 자동으로 생성된 코드를 다시 노트북으로 내보냅니다.
이 페이지의 목표는 Data Wrangler를 빠르고 효과적으로 시작할 수 있도록 돕는 것입니다.
환경 설정
- 아직 설치하지 않았다면 Python을 설치하세요. (참고: Data Wrangler는 Python 버전 3.8 이상만 지원합니다.)
- Data Wrangler 확장 프로그램 설치
Data Wrangler를 처음 실행하면 연결할 Python 커널을 선택하라는 메시지가 표시됩니다. 또한 Pandas와 같은 필수 Python 패키지가 설치되어 있는지 확인하기 위해 컴퓨터와 환경을 확인합니다.
Data Wrangler 열기
Data Wrangler에 있는 동안에는 항상 격리된 환경에 있습니다. 즉, 데이터를 안전하게 탐색하고 변환할 수 있습니다. 변경 사항을 명시적으로 내보낼 때까지 원본 데이터 세트는 수정되지 않습니다.
Jupyter Notebook에서 Data Wrangler 시작
노트북에 Pandas 데이터 프레임이 있는 경우 df.head(), df.tail(), display(df), print(df) 및 df 중 하나를 실행한 후 셀 아래에 'df'를 Data Wrangler에서 열기 버튼(여기서 df는 데이터 프레임의 변수 이름)이 표시됩니다.
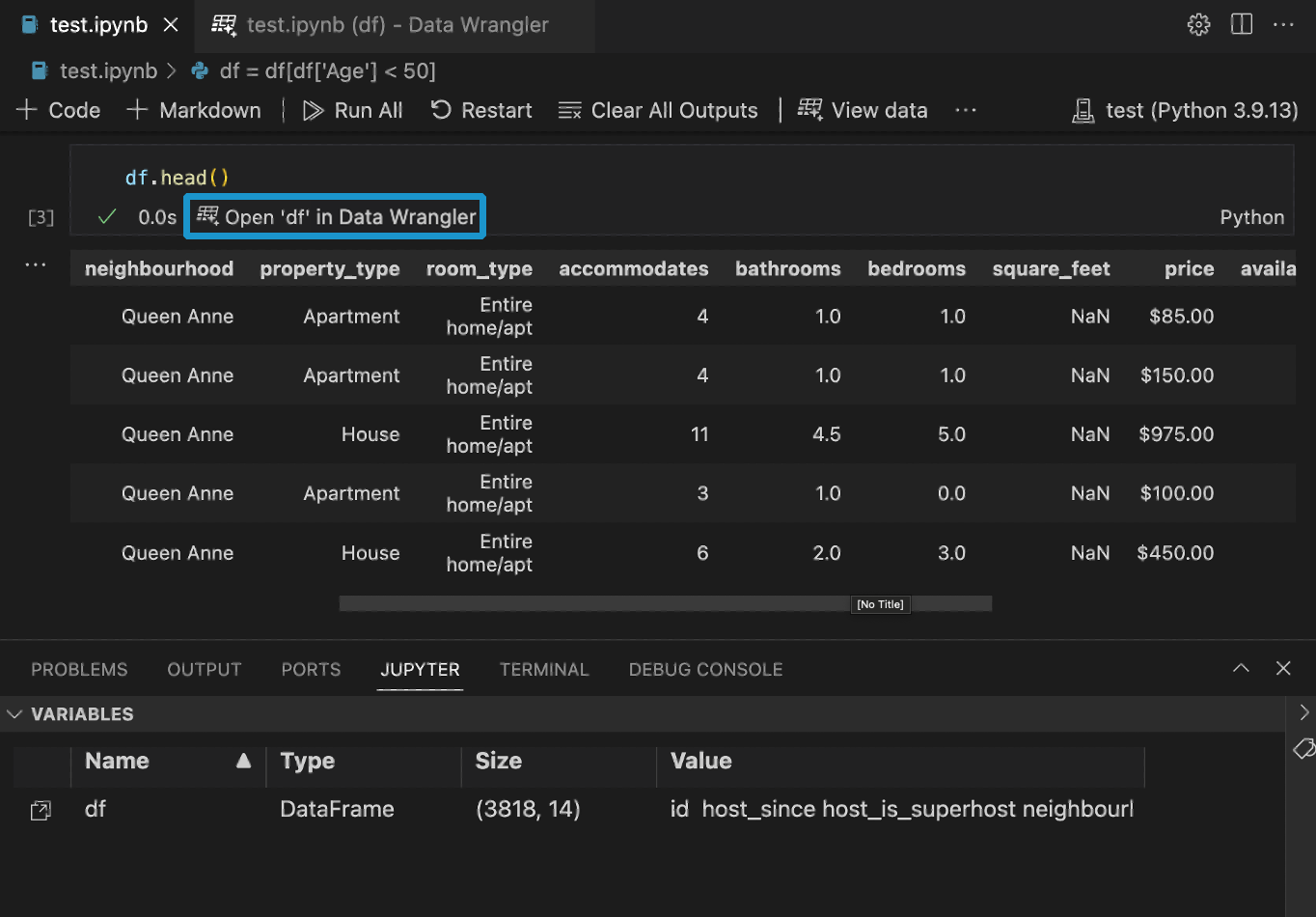
파일에서 직접 Data Wrangler 시작
로컬 파일(예: .csv)에서 직접 Data Wrangler를 시작할 수도 있습니다. 이렇게 하려면 열려는 파일이 포함된 폴더를 VS Code에서 엽니다. 파일 탐색기 보기에서 파일을 마우스 오른쪽 버튼으로 클릭하고 Data Wrangler에서 열기를 클릭합니다.

UI 둘러보기
Data Wrangler는 데이터를 처리할 때 두 가지 모드를 가집니다. 각 모드에 대한 자세한 내용은 아래 후속 섹션에서 설명합니다.
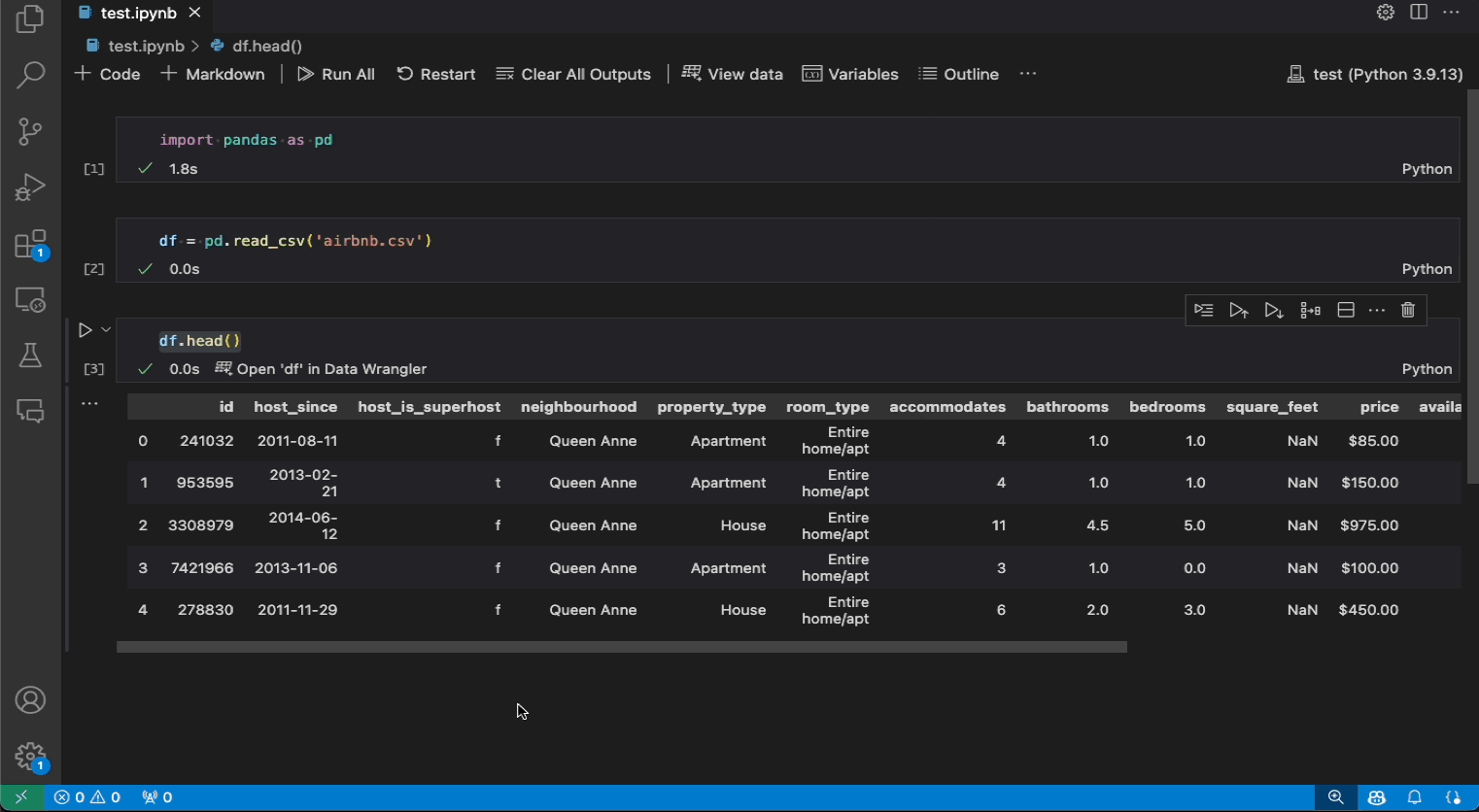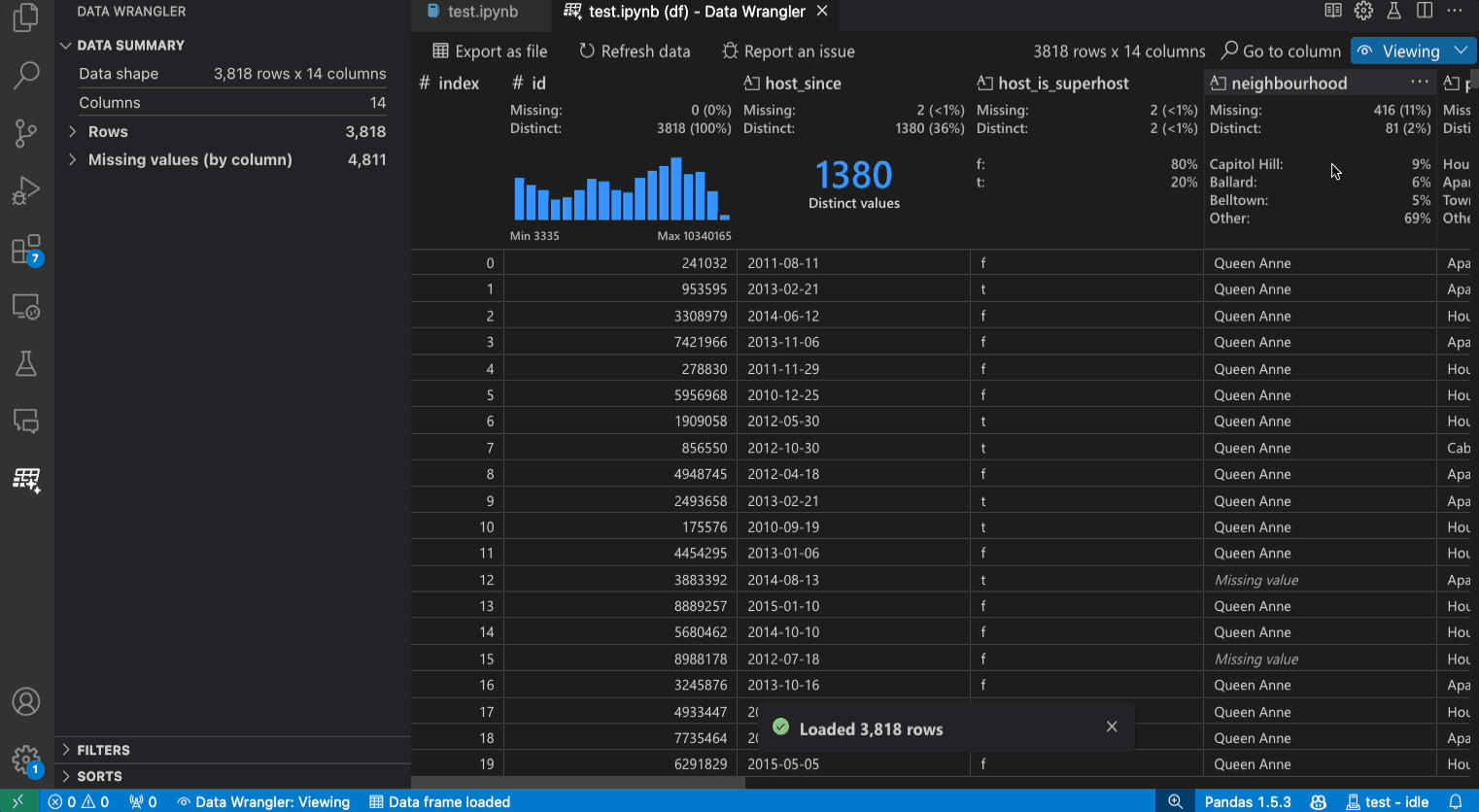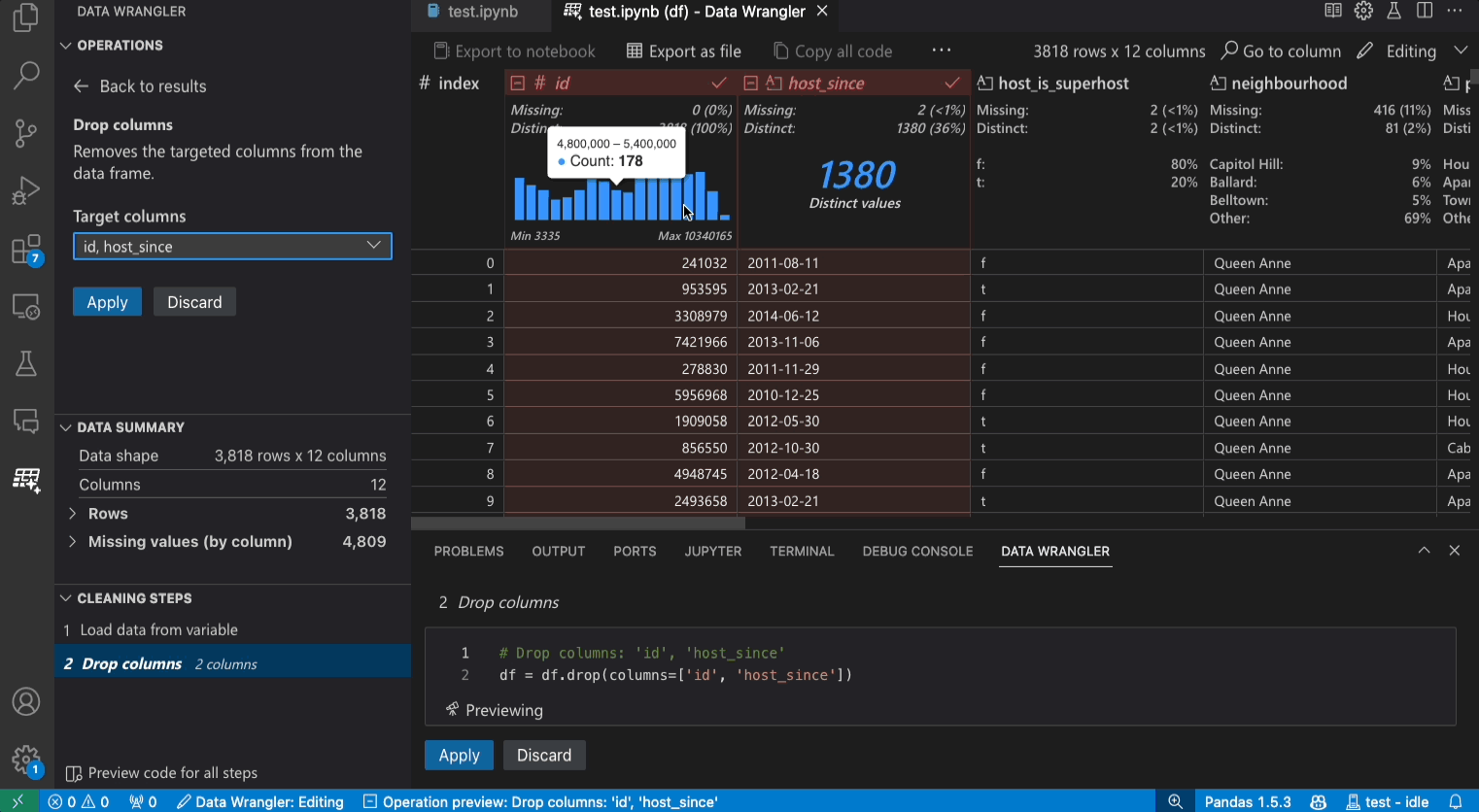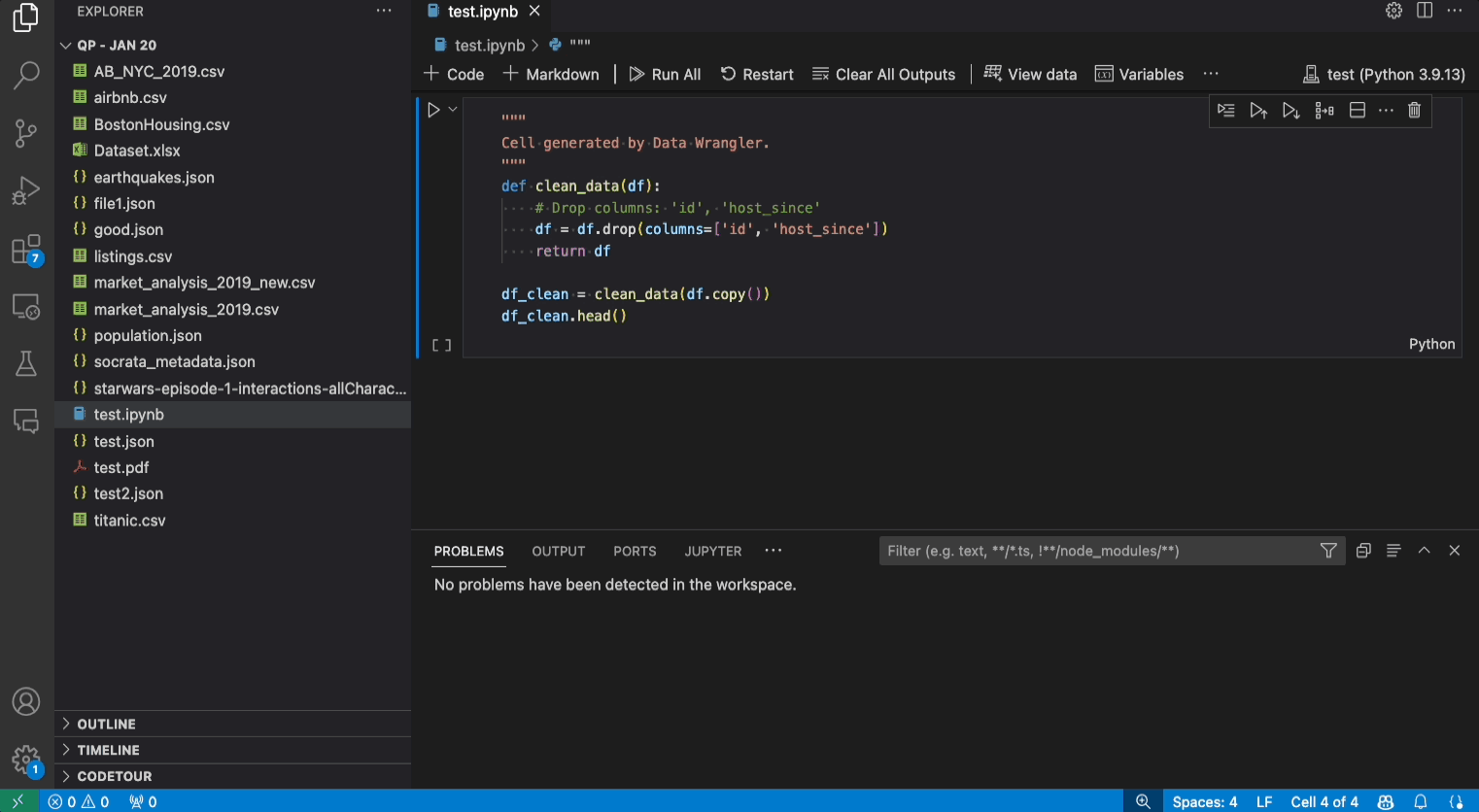
- 보기 모드: 보기 모드는 데이터를 빠르게 보고, 필터링하고, 정렬할 수 있도록 인터페이스를 최적화합니다. 이 모드는 데이터 세트에 대한 초기 탐색에 매우 유용합니다.
- 편집 모드: 편집 모드는 데이터 세트에 변환, 정리 또는 수정을 적용할 수 있도록 인터페이스를 최적화합니다. 인터페이스에서 이러한 변환을 적용하면 Data Wrangler는 관련 Pandas 코드를 자동으로 생성하며, 이를 다시 노트북으로 내보내 재사용할 수 있습니다.
참고: 기본적으로 Data Wrangler는 보기 모드로 열립니다. 설정을 편집하여 이 동작을 변경할 수 있습니다. .
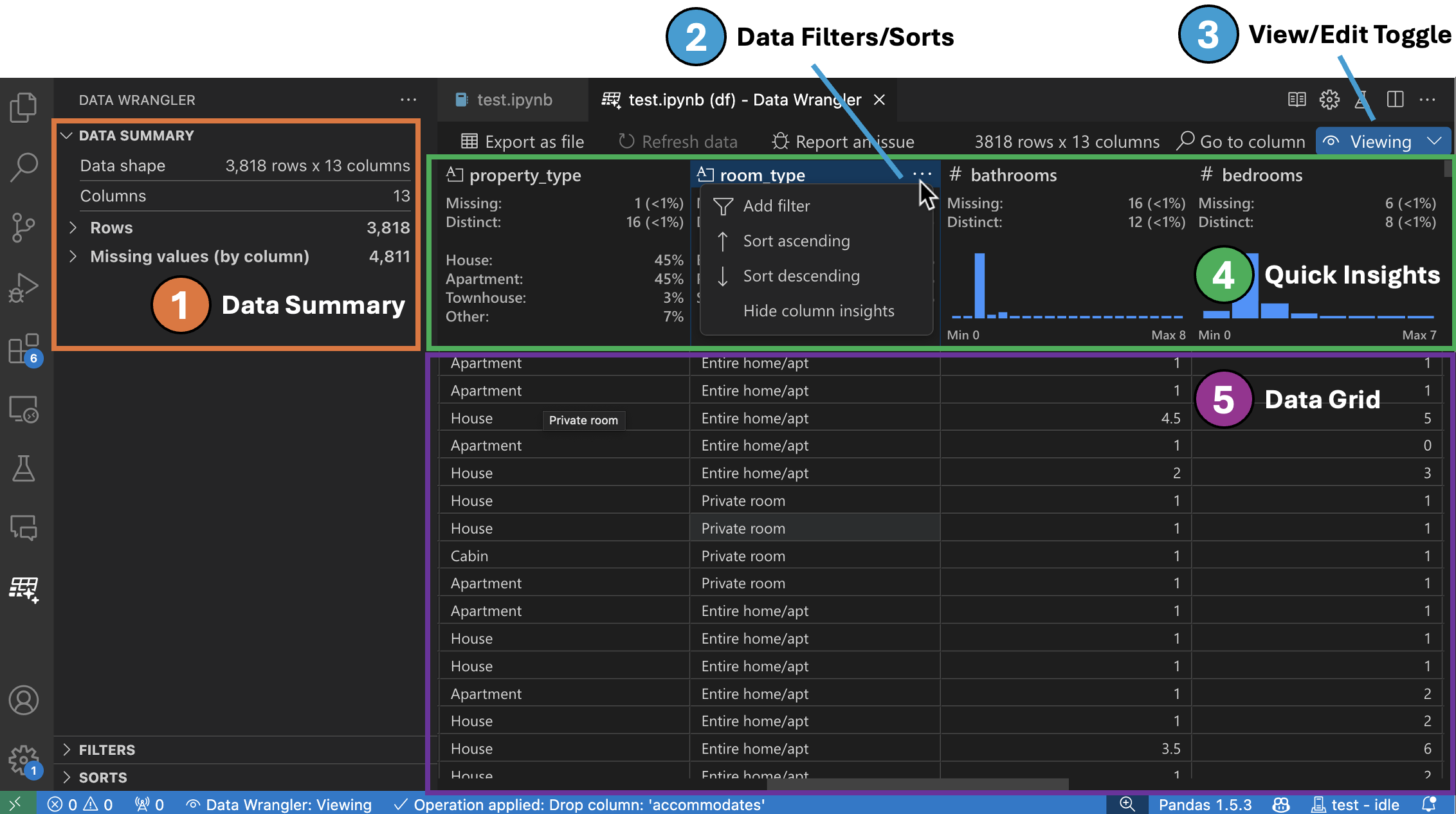
보기 모드 인터페이스
-
데이터 요약 패널은 전체 데이터 세트 또는 특정 열(선택된 경우)에 대한 자세한 요약 통계를 표시합니다.
-
열의 헤더 메뉴에서 데이터 필터/정렬을 적용할 수 있습니다.
-
Data Wrangler의 보기 또는 편집 모드를 전환하여 내장된 데이터 작업에 액세스할 수 있습니다.
-
빠른 인사이트 헤더는 각 열에 대한 유용한 정보를 빠르게 볼 수 있는 곳입니다. 열의 데이터 유형에 따라 빠른 인사이트는 데이터의 분포 또는 데이터 포인트의 빈도, 누락된 값 및 고유한 값을 표시합니다.
-
데이터 그리드는 전체 데이터 세트를 볼 수 있는 스크롤 가능한 창을 제공합니다.
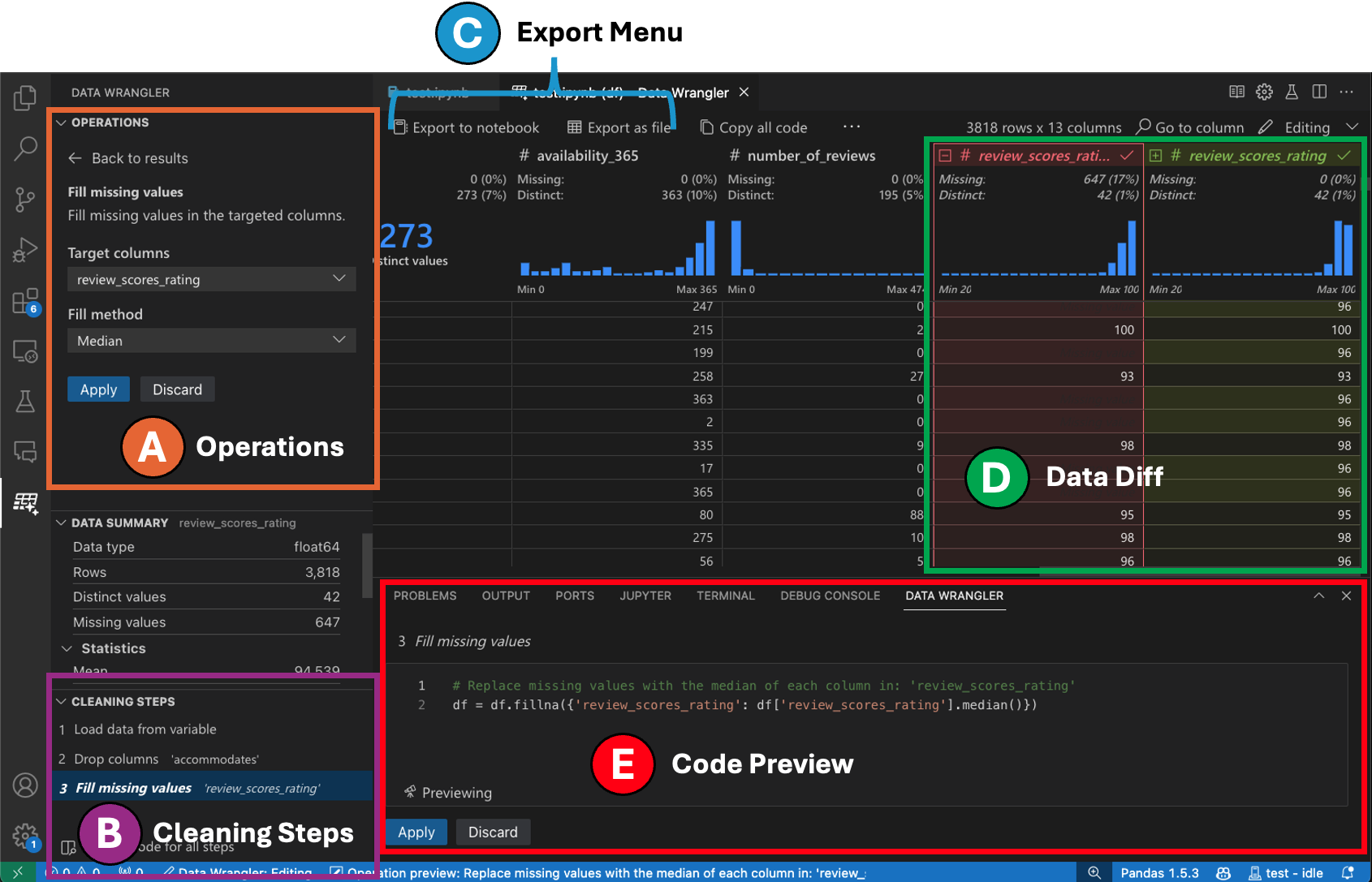
편집 모드 인터페이스
편집 모드로 전환하면 Data Wrangler에서 추가 기능과 사용자 인터페이스 요소가 활성화됩니다. 다음 스크린샷에서는 Data Wrangler를 사용하여 마지막 열의 누락된 값을 해당 열의 중간값으로 바꾸는 방법을 보여줍니다.
-
작업 패널은 Data Wrangler의 모든 내장 데이터 작업을 검색할 수 있는 곳입니다. 작업은 범주별로 구성됩니다.
-
정리 단계 패널은 이전에 적용된 모든 작업 목록을 보여줍니다. 사용자는 특정 작업을 실행 취소하거나 *가장 최근* 작업을 편집할 수 있습니다. 단계를 선택하면 데이터 그리드에서 변경 사항이 강조 표시되고 해당 작업과 관련된 생성된 코드가 표시됩니다.
-
내보내기 메뉴를 사용하면 코드를 Jupyter Notebook으로 다시 내보내거나 데이터를 새 파일로 내보낼 수 있습니다.
-
작업을 선택하고 데이터에 대한 해당 효과를 미리 볼 때 데이터 그리드에 변경된 내용을 보여주는 데이터 차이 보기가 겹쳐 표시됩니다.
-
코드 미리보기 섹션은 작업을 선택했을 때 Data Wrangler가 생성한 Python 및 Pandas 코드를 보여줍니다. 작업이 선택되지 않은 경우 비어 있습니다. 생성된 코드를 편집하면 데이터 그리드에 데이터에 대한 효과가 강조 표시됩니다.
예시: 데이터 세트의 누락된 값 바꾸기
데이터 세트가 주어졌을 때 일반적인 데이터 정리 작업 중 하나는 데이터 내의 누락된 값을 처리하는 것입니다. 아래 예시는 Data Wrangler를 사용하여 열의 누락된 값을 해당 열의 중간값으로 바꾸는 방법을 보여줍니다. 변환은 인터페이스를 통해 수행되지만 Data Wrangler는 누락된 값 바꾸기에 필요한 Python 및 Pandas 코드도 자동으로 생성합니다.
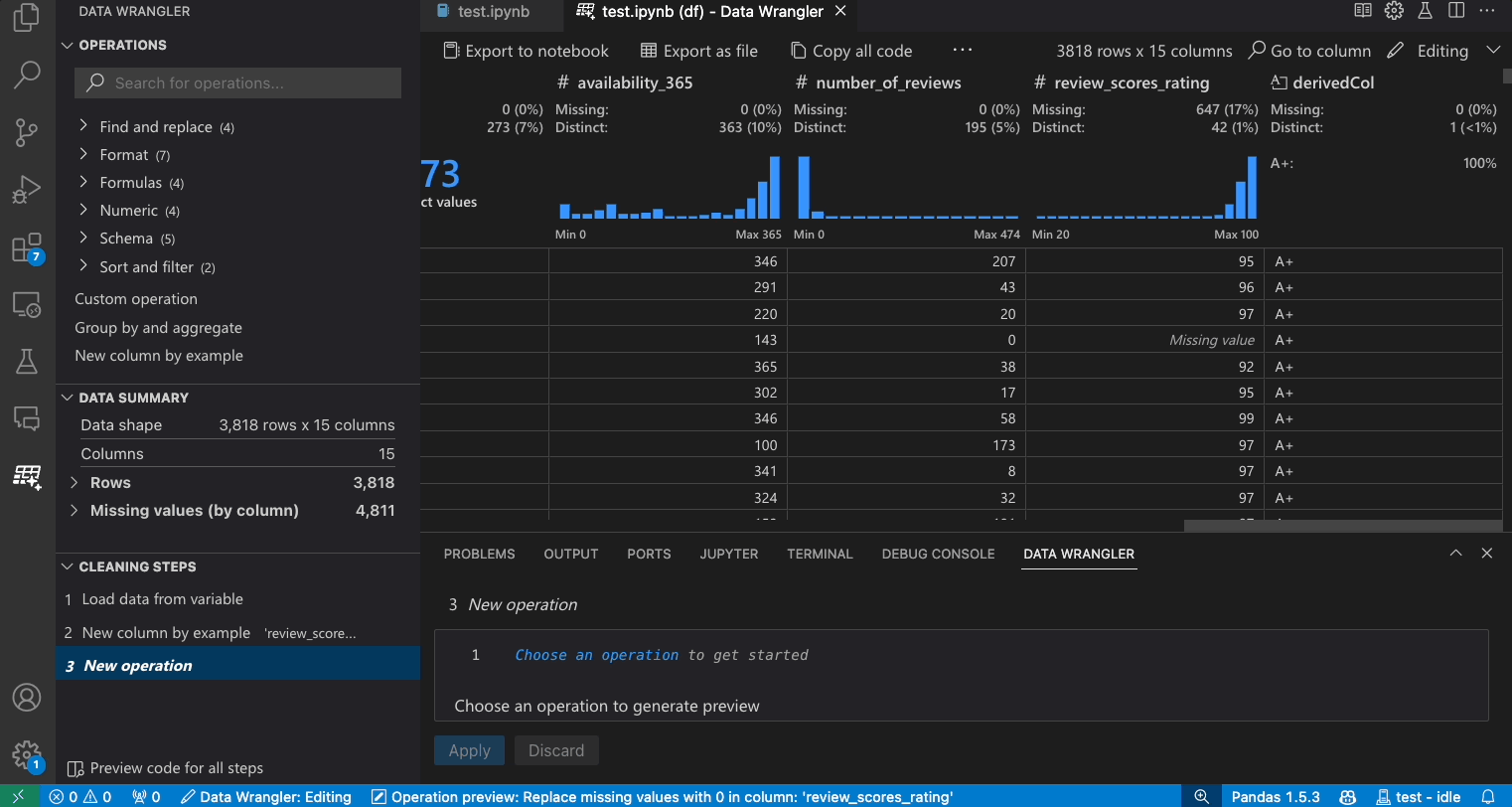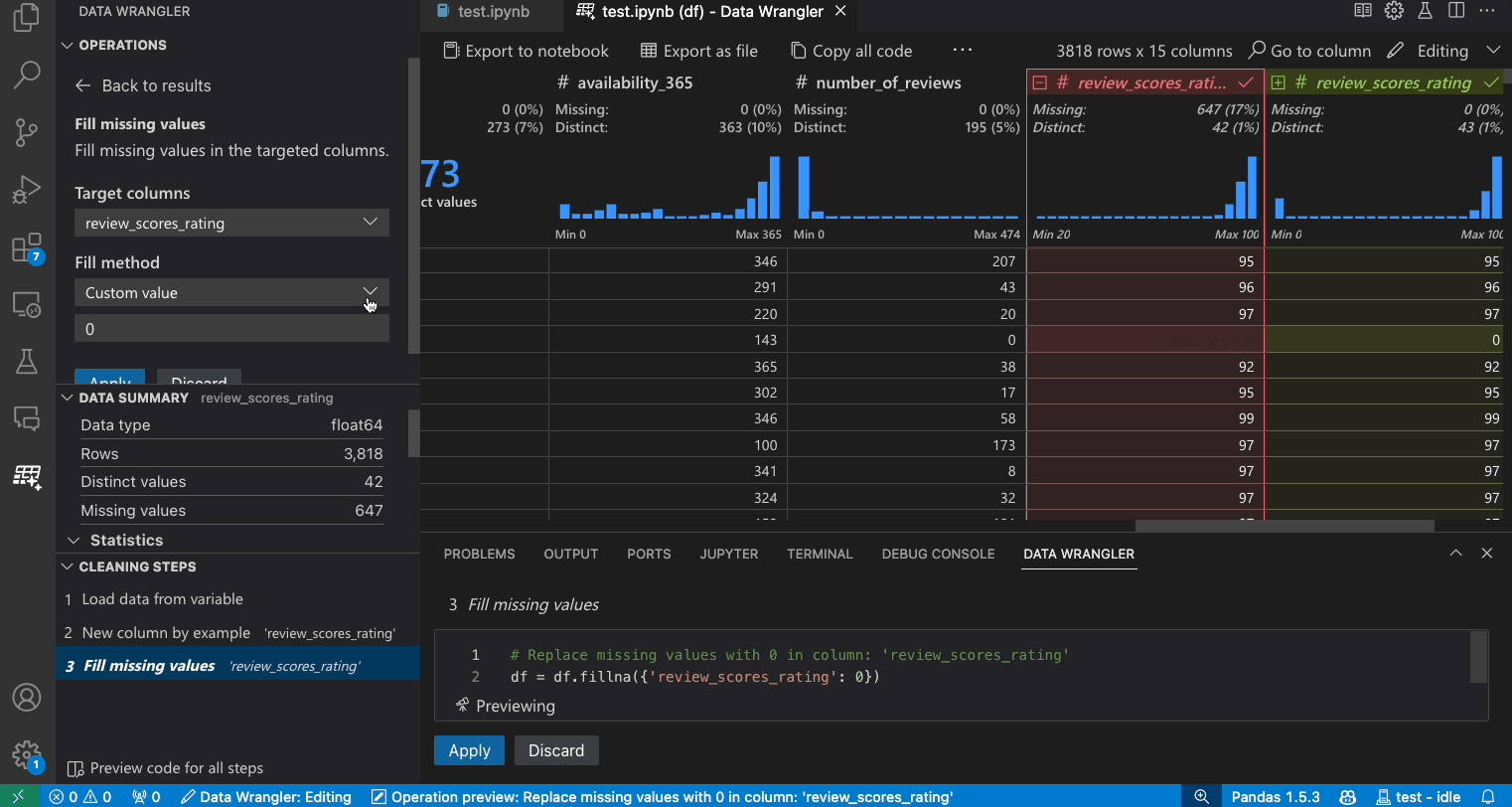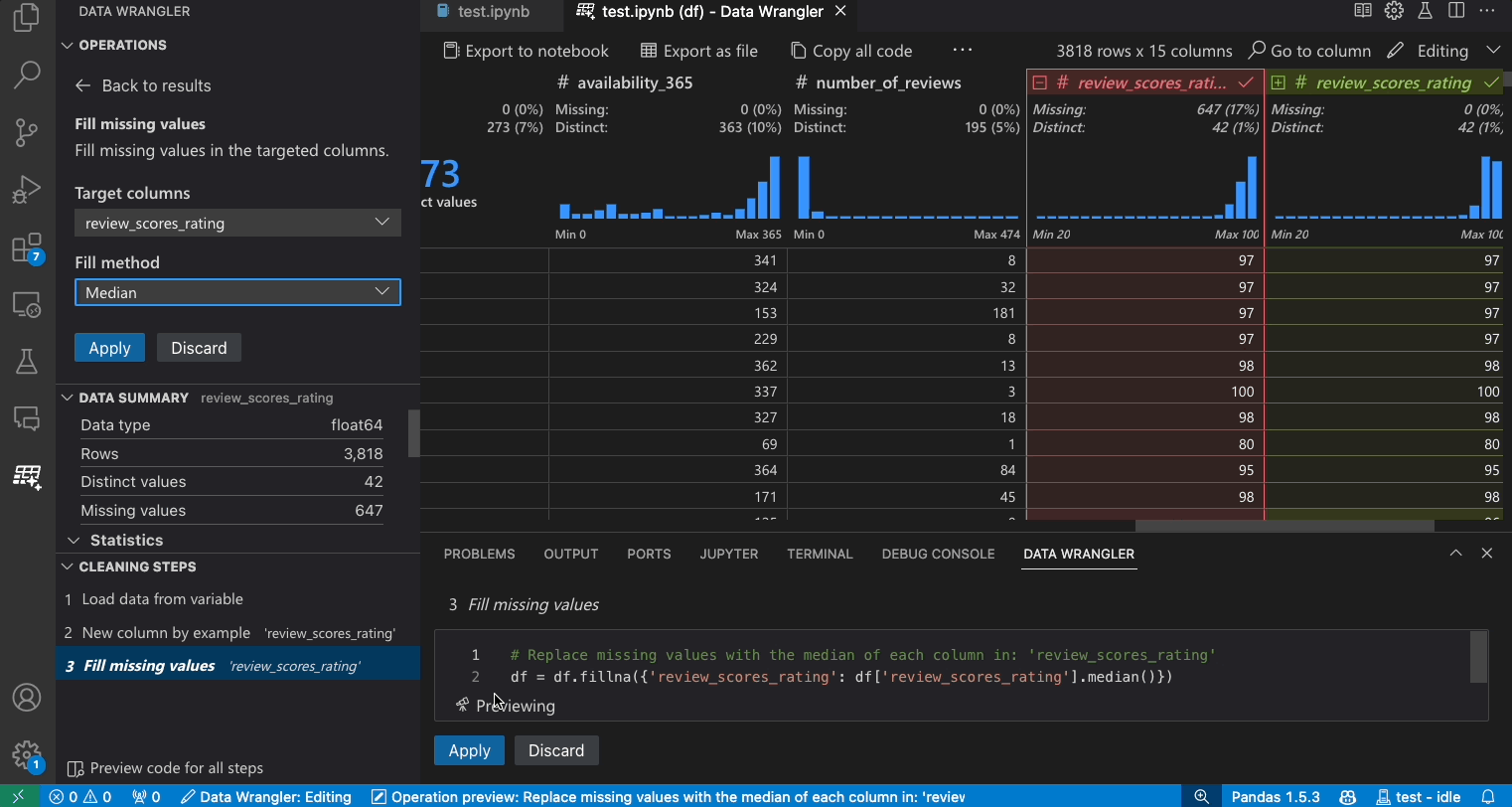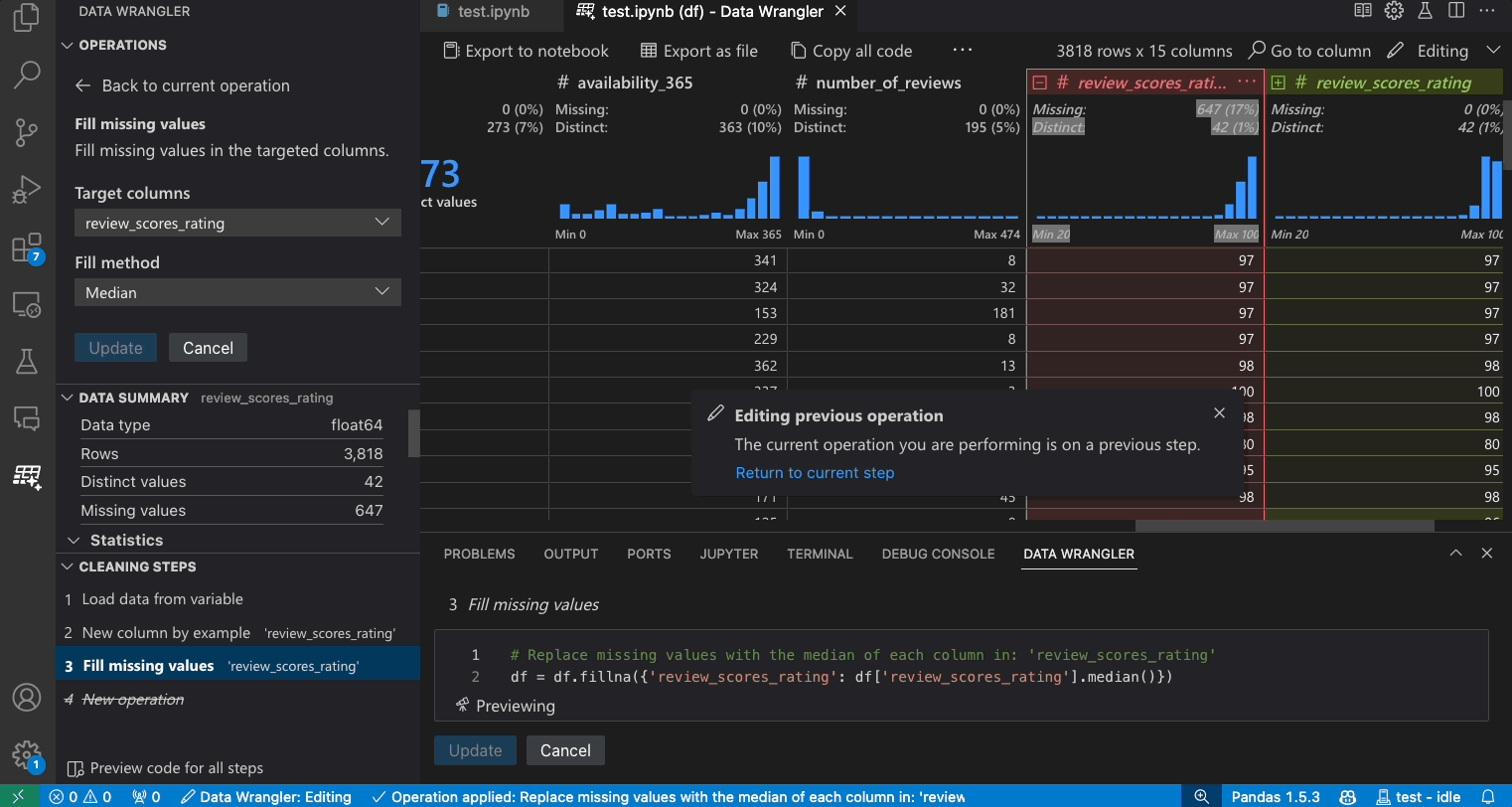
- 작업 패널에서 누락된 값 채우기 작업을 검색합니다.
- 매개변수에서 누락된 값을 무엇으로 바꿀지 지정합니다. 이 경우 열의 중간값으로 누락된 값을 바꿀 것입니다.
- 데이터 그리드가 데이터 차이에서 올바른 변경 사항을 보여주는지 확인합니다.
- Data Wrangler가 생성한 코드가 의도한 대로인지 확인합니다.
- 작업을 적용하면 정리 단계 기록에 추가됩니다.
다음 단계
이 페이지에서는 Data Wrangler를 빠르게 시작하는 방법을 다루었습니다. Data Wrangler가 현재 지원하는 모든 내장 작업이 포함된 Data Wrangler의 전체 문서 및 튜토리얼은 다음 페이지를 참조하십시오.