VS Code용 AI Toolkit으로 모델 변환
모델 변환은 로컬 Windows 플랫폼에서 사전 구축된 머신러닝 모델을 변환, 양자화, 최적화 및 평가하는 데 도움이 되는 통합 개발 환경입니다. Hugging Face와 같은 소스에서 변환된 모델을 위한 능률적이고 종단 간 경험을 제공하며, 이를 최적화하고 NPU, GPU 및 CPU로 구동되는 로컬 장치에서 추론을 가능하게 합니다.
전제 조건
- VS Code가 설치되어 있어야 합니다. VS Code 설정을 위해 다음 단계를 따르세요.
- AI Toolkit 확장이 설치되어 있어야 합니다. 자세한 내용은 AI Toolkit 설치를 참조하세요.
프로젝트 만들기
모델 변환에서 프로젝트를 만드는 것은 머신러닝 모델을 변환, 최적화, 양자화 및 평가하기 위한 첫 번째 단계입니다.
-
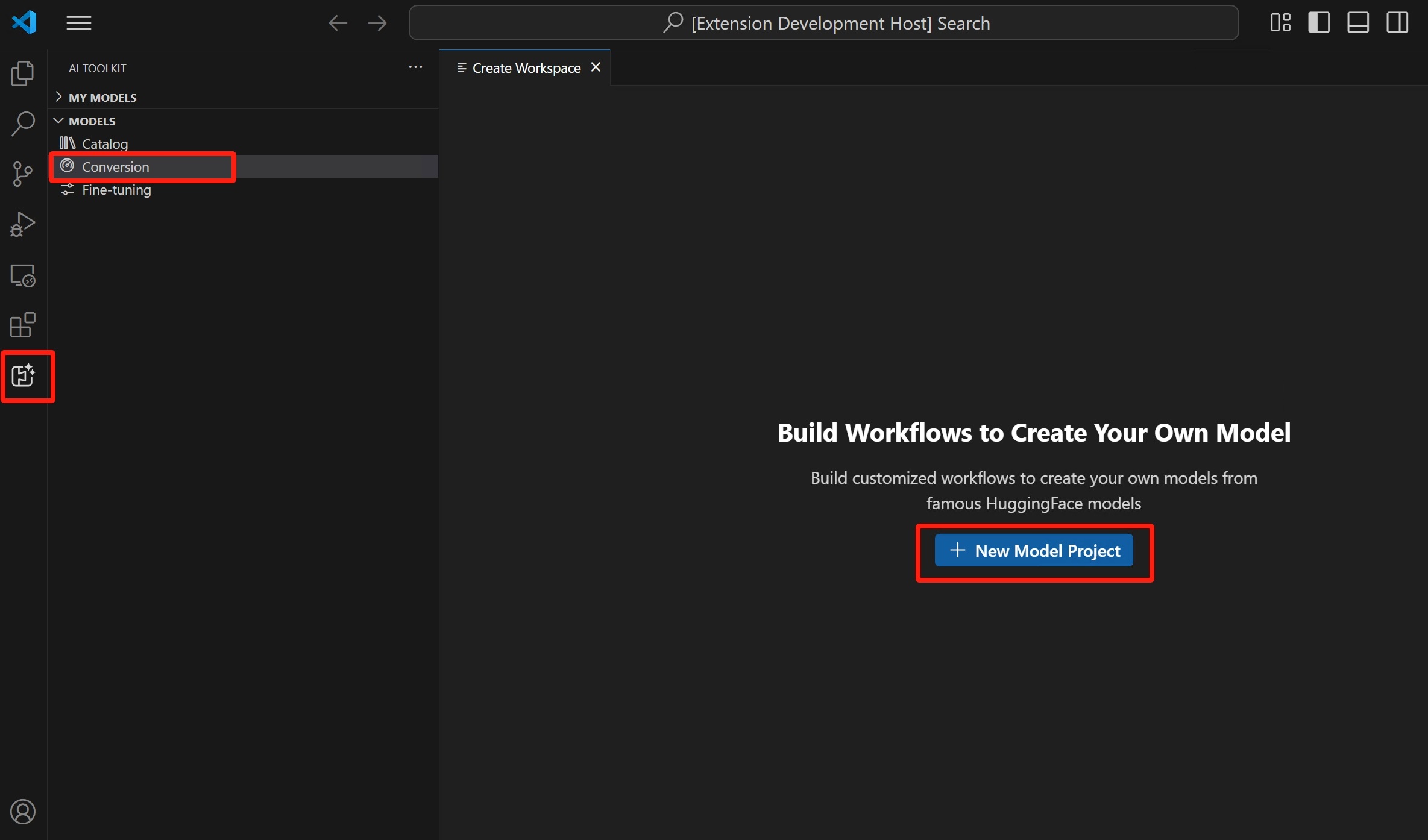
AI Toolkit 보기를 열고 모델 > 변환을 선택하여 모델 변환을 시작합니다.
-
새 모델 프로젝트를 선택하여 새 프로젝트를 시작합니다.
-
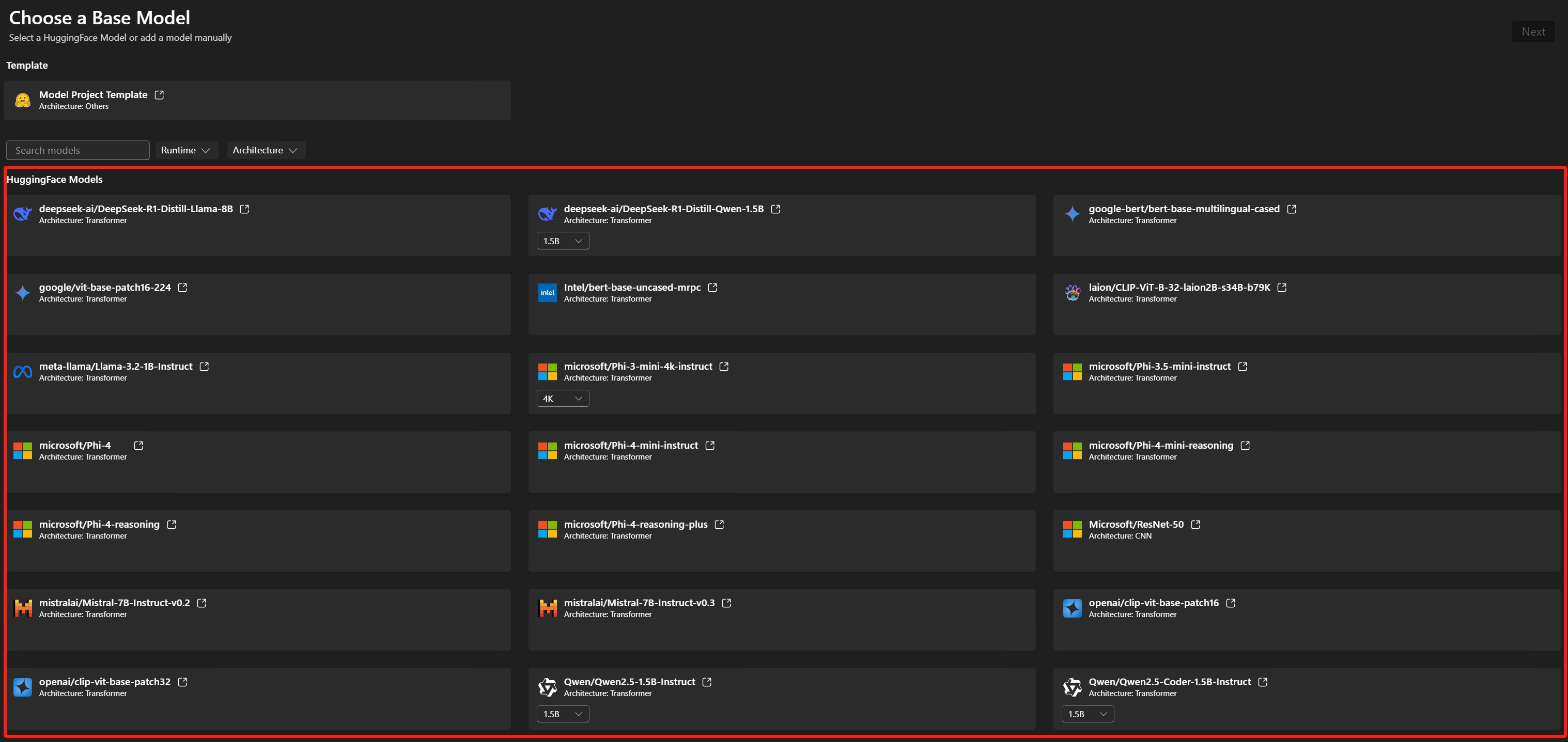
기본 모델 선택
Hugging Face 모델: 지원되는 모델 목록에서 사전 정의된 레시피가 있는 기본 모델을 선택합니다.모델 템플릿: 모델이 기본 모델에 포함되어 있지 않은 경우 사용자 지정 레시피를 위한 빈 템플릿을 선택합니다(고급 시나리오).
-
프로젝트 세부 정보 입력: 고유한 프로젝트 폴더 및 프로젝트 이름.
선택한 위치에 지정된 프로젝트 이름의 새 폴더가 생성되어 프로젝트 파일을 저장합니다.
모델 프로젝트를 처음 만들 때는 환경 설정에 시간이 걸릴 수 있습니다. 환경 설정을 완료하지 않아도 괜찮습니다. 준비가 되었을 때 환경을 다시 설정하도록 선택할 수 있습니다. 
각 프로젝트에는 README.md 파일이 포함되어 있습니다. 닫은 경우 작업 영역을 통해 다시 열 수 있습니다. 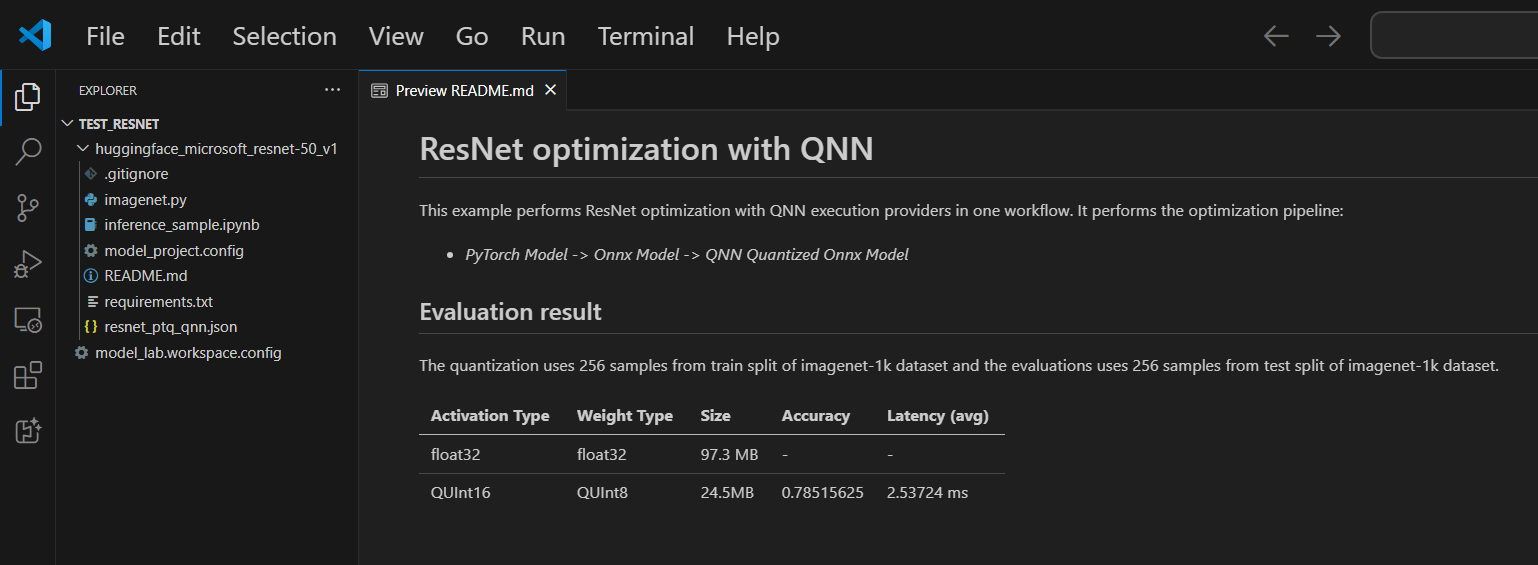
지원되는 모델
모델 변환은 현재 PyTorch 형식의 상위 Hugging Face 모델을 포함하여 계속 증가하는 모델 목록을 지원합니다. 자세한 모델 목록은 모델 목록을 참조하세요.
(선택 사항) 기존 프로젝트에 모델 추가
-
모델 프로젝트 열기
-
모델 > 변환을 선택한 다음 오른쪽 창에서 모델 추가를 선택합니다.
-
기본 모델 또는 템플릿을 선택한 다음 추가를 선택합니다.
새 모델 파일이 포함된 폴더가 현재 프로젝트 폴더에 생성됩니다.
(선택 사항) 새 모델 프로젝트 만들기
-
모델 프로젝트 열기
-
모델 > 변환을 선택한 다음 오른쪽 창에서 새 프로젝트를 선택합니다.
-
또는 현재 모델 프로젝트를 닫고 처음부터 새 프로젝트를 만듭니다.
(선택 사항) 모델 프로젝트 삭제
-
모델 프로젝트를 열고 모델 > 변환을 선택합니다.
-
오른쪽 상단 보기에서 줄임표(...)를 선택한 다음 삭제를 선택하여 현재 선택한 모델 프로젝트를 삭제합니다.
워크플로 실행
모델 변환에서 워크플로를 실행하는 것은 사전 구축된 ML 모델을 최적화되고 양자화된 ONNX 모델로 변환하는 핵심 단계입니다.
-
VS Code에서 파일 > 폴더 열기를 선택하여 모델 프로젝트 폴더를 엽니다.
-
워크플로 구성 검토
- 모델 > 변환 선택
- 변환 레시피를 보려면 워크플로 템플릿을 선택합니다.
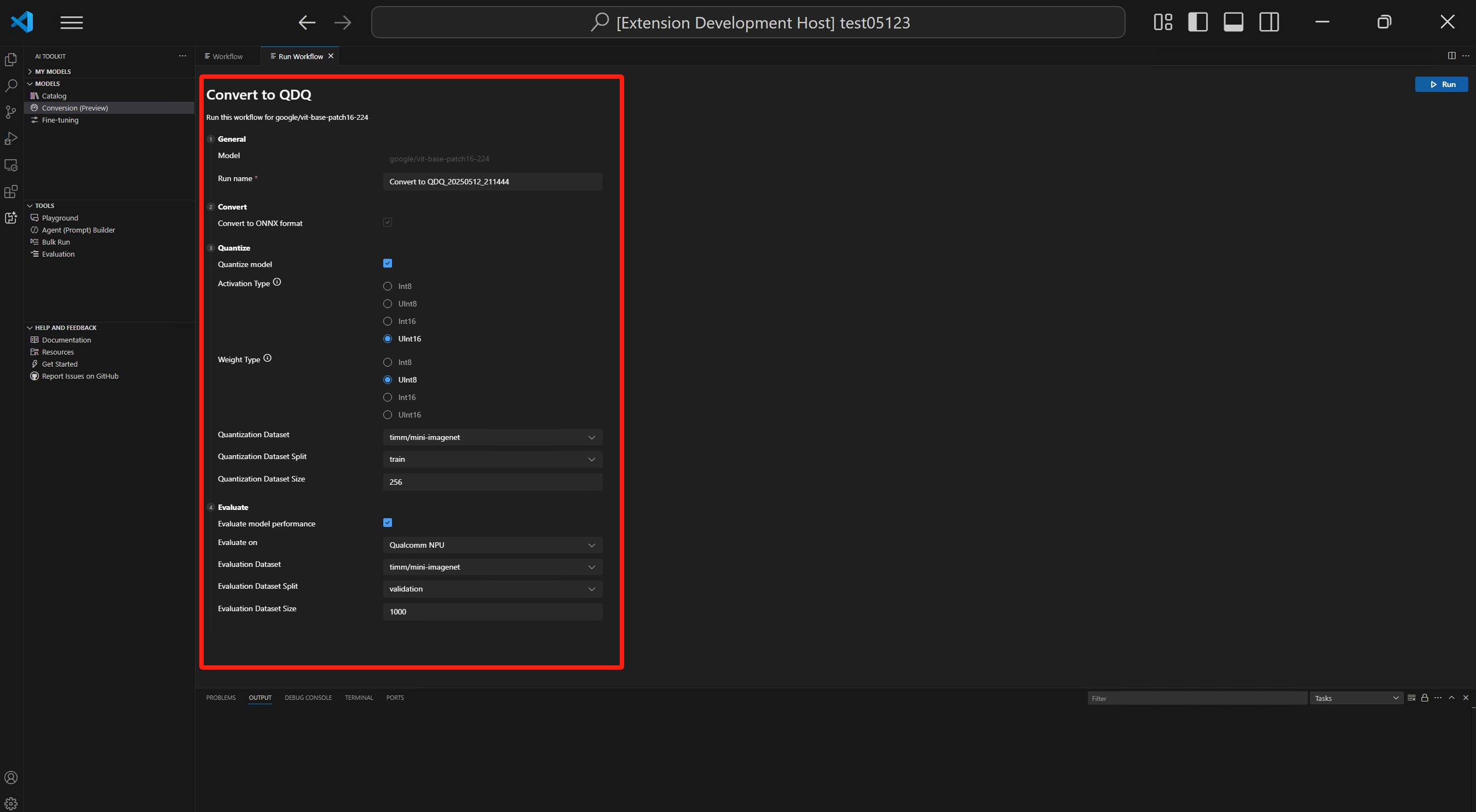
변환
워크플로는 항상 모델을 ONNX 형식으로 변환하는 변환 단계를 실행합니다. 이 단계는 비활성화할 수 없습니다.
양자화
이 섹션을 통해 양자화 매개변수를 구성할 수 있습니다.
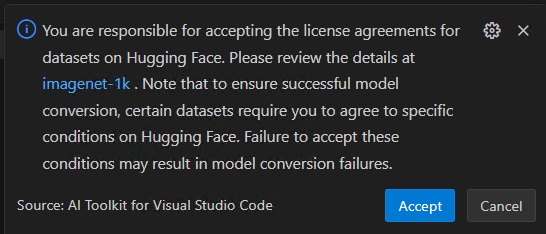
중요Hugging Face 준수 경고: 양자화 중에 보정 데이터 세트가 필요합니다. 진행하기 전에 라이선스 약관에 동의하라는 메시지가 표시될 수 있습니다. 알림을 놓치면 실행 프로세스가 일시 중지되고 입력이 대기합니다. 알림이 활성화되었는지, 필수 라이선스에 동의했는지 확인하십시오.
-
활성화 유형: 신경망의 각 레이어 중간 출력(활성화)을 나타내는 데 사용되는 데이터 유형입니다.
-
가중치 유형: 모델의 학습된 매개변수(가중치)를 나타내는 데 사용되는 데이터 유형입니다.
-
양자화 데이터 세트: 양자화에 사용되는 보정 데이터 세트입니다.
워크플로에서 라이선스 계약 승인이 필요한 데이터 세트(예: ImageNet-1k)를 사용하는 경우 진행하기 전에 데이터 세트 페이지에서 해당 약관에 동의하라는 메시지가 표시됩니다. 이는 법적 준수에 필요합니다.
-
HuggingFace 액세스 토큰 버튼을 선택하여 Hugging Face 액세스 토큰을 가져옵니다.
-
열기를 선택하여 Hugging Face 웹사이트를 엽니다.
-
Hugging Face 포털에서 토큰을 얻고 빠른 선택에 붙여넣습니다. Enter를 누릅니다.

-
-
양자화 데이터 세트 분할: 데이터 세트에는 유효성 검사, 훈련 및 테스트와 같은 다른 분할이 있을 수 있습니다.
-
양자화 데이터 세트 크기: 모델을 양자화하는 데 사용되는 데이터의 양입니다.
활성화 및 가중치 유형에 대한 자세한 내용은 데이터 유형 선택을 참조하십시오.
이 섹션을 비활성화할 수도 있습니다. 이 경우 워크플로는 모델을 ONNX 형식으로 변환하지만 모델을 양자화하지는 않습니다.
평가
이 섹션에서는 모델이 변환된 플랫폼에 관계없이 평가에 사용할 실행 공급자(EP)를 선택해야 합니다.
- 평가 대상: 모델을 평가하려는 대상 장치입니다. 가능한 값은 다음과 같습니다.
- Qualcomm NPU: 이를 사용하려면 호환되는 Qualcomm 장치가 필요합니다.
- AMD NPU: 이를 사용하려면 지원되는 AMD NPU가 있는 장치가 필요합니다.
- Intel CPU/GPU/NPU: 이를 사용하려면 지원되는 Intel CPU/GPU/NPU가 있는 장치가 필요합니다.
- NVIDIA TRT for RTX: 이를 사용하려면 TensorRT for RTX를 지원하는 Nvidia GPU가 있는 장치가 필요합니다.
- DirectML: 이를 사용하려면 DirectML을 지원하는 GPU가 있는 장치가 필요합니다.
- CPU: 모든 CPU에서 작동할 수 있습니다.
- 평가 데이터 세트: 평가에 사용되는 데이터 세트입니다.
- 평가 데이터 세트 분할: 데이터 세트에는 유효성 검사, 훈련 및 테스트와 같은 다른 분할이 있을 수 있습니다.
- 평가 데이터 세트 크기: 모델을 평가하는 데 사용되는 데이터의 양입니다.
이 섹션을 비활성화할 수도 있습니다. 이 경우 워크플로는 모델을 ONNX 형식으로 변환하지만 모델을 평가하지는 않습니다.
-
실행을 선택하여 워크플로 실행
추적을 쉽게 하기 위해 워크플로 이름과 타임스탬프를 사용하여 기본 작업 이름이 생성됩니다(예:
bert_qdq_2025-05-06_20-45-00).작업 실행 중에 상태 표시줄이나 기록 보드의 작업 아래의 점 세 개 메뉴를 선택하고 실행 중지를 선택하여 작업을 취소할 수 있습니다.
Hugging Face 준수 경고: 양자화 중에 보정 데이터 세트가 필요합니다. 진행하기 전에 라이선스 약관에 동의하라는 메시지가 표시될 수 있습니다. 알림을 놓치면 실행 프로세스가 일시 중지되고 입력이 대기합니다. 알림이 활성화되었고 필수 라이선스에 동의했는지 확인하십시오.
-
(선택 사항) 클라우드에서 모델 변환 실행
클라우드 변환을 사용하면 로컬 컴퓨터에 충분한 컴퓨팅 또는 저장 용량이 없을 때 클라우드에서 모델 변환 및 양자화를 실행할 수 있습니다. 클라우드 변환을 사용하려면 Azure 구독이 필요합니다.
-
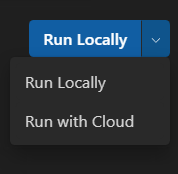
오른쪽 상단의 드롭다운에서 클라우드에서 실행을 선택합니다. 클라우드 환경에는 추론을 위한 대상 프로세서가 없으므로 평가 섹션이 비활성화됩니다.
-
AI Toolkit은 먼저 클라우드 변환을 위한 Azure 리소스가 준비되었는지 확인합니다. 필요한 경우 Azure 구독 및 리소스 그룹에 대한 프롬프트가 표시되어 Azure 리소스를 프로비저닝합니다.

-
프로비저닝이 완료되면 프로비저닝 구성이 작업 영역 루트 폴더의
model_lab.workspace.provision.config에 저장됩니다. 이 정보는 Azure 리소스를 재사용하고 클라우드 변환 프로세스를 가속화하기 위해 캐시됩니다. 새 리소스를 사용하려면 이 파일을 삭제하고 클라우드 변환을 다시 실행하세요. -
Azure Container App(ACA) 작업이 트리거되어 클라우드 변환을 실행합니다. 실행 중인 작업의 경우 다음을 수행할 수 있습니다.
- 상태 링크를 선택하여 Azure ACA 작업 실행 기록 페이지로 이동합니다.
- 로그를 선택하여 Azure Log Analytics로 이동합니다.
- 새로고침 버튼을 선택하여 현재 작업 상태를 가져옵니다.

-
LLM 모델 변환을 위한 GPU가 없는 경우 클라우드에서 실행을 사용할 수 있습니다. 클라우드에서 실행 옵션은 모델 변환 및 양자화만 지원합니다. 평가를 위해 변환된 모델을 로컬 머신으로 다운로드해야 합니다.
클라우드에서 실행은 DirectML 또는 NVIDIA TRT for RTX 워크플로를 사용한 모델 변환을 지원하지 않습니다.
권장 열에는 장치가 변환된 모델을 실행할 준비가 되었는지 여부에 따라 권장되는 워크플로가 표시됩니다. 여전히 원하는 워크플로를 선택할 수 있습니다. 모델 변환 및 양자화: LLM 모델을 제외한 모든 장치에서 워크플로를 실행할 수 있습니다. 양자화 구성은 NPU에 최적화되어 있습니다. 대상 시스템이 NPU가 아닌 경우 이 단계를 선택 취소하는 것이 좋습니다.
LLM 모델 양자화: LLM 모델을 양자화하려면 Nvidia GPU가 필요합니다.
GPU가 있는 다른 장치에서 모델을 양자화하려면 자체적으로 환경을 설정할 수 있습니다. ManualConversionOnGPU를 참조하세요. 양자화 단계만 GPU가 필요합니다. 양자화 후 NPU 또는 CPU에서 모델을 평가할 수 있습니다.
재평가를 위한 팁
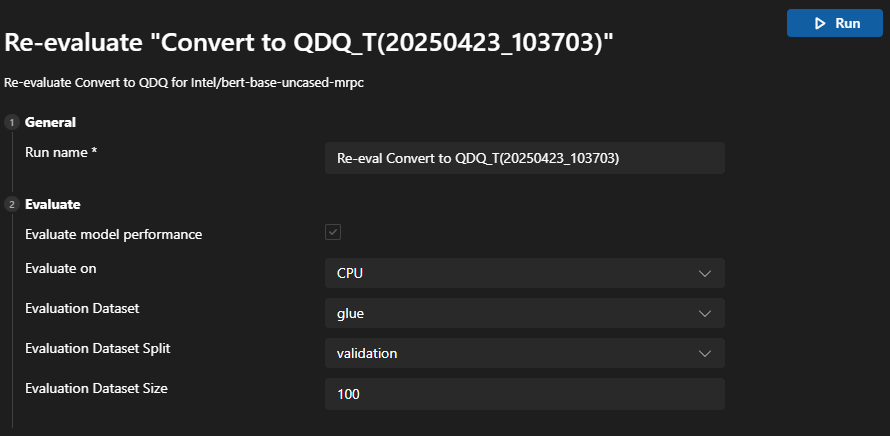
모델이 성공적으로 변환된 후 재평가 기능을 사용하여 모델 변환 없이 다시 평가를 수행할 수 있습니다.
기록 보드로 이동하여 모델 실행 작업을 찾습니다. 작업 아래의 점 세 개 메뉴를 선택하여 모델을 재평가합니다.
재평가를 위해 다른 EP 또는 데이터 세트를 선택할 수 있습니다.
실패한 작업에 대한 팁
작업이 취소되거나 실패한 경우 작업 이름을 선택하여 워크플로를 조정하고 작업을 다시 실행할 수 있습니다. 실수로 덮어쓰는 것을 방지하기 위해 각 실행은 자체 구성 및 결과가 있는 새 기록 폴더를 생성합니다.
일부 워크플로에서는 먼저 Hugging Face에 로그인해야 할 수 있습니다. huggingface_hub.errors.LocalTokenNotFoundError: Token is required ('token=True'), but no token found. You need to provide a token or be logged in to Hugging Face with 'hf auth login' or 'huggingface_hub.login'와 같은 출력으로 작업이 실패한 경우 https://huggingface.co/settings/tokens로 이동하여 로그인 프로세스를 완료하는 지침을 따르고 다시 시도하십시오.
재평가가 Microsoft Visual C++ Redistributable is not installed와 같은 경고 출력으로 실패한 경우 다음 패키지를 수동으로 설치해야 합니다.
- Microsoft Visual C++ 재배포 가능 패키지
- (ARM64의 경우 선택 사항) Microsoft C++ 빌드 도구에서 다운로드합니다. 설치 중에
C++를 사용한 데스크톱 개발워크로드도 확인하세요.
결과 보기
변환의 기록 보드는 모든 워크플로 실행을 추적, 검토 및 관리하는 중앙 대시보드입니다. 모델 변환 및 평가를 실행할 때마다 기록 보드에 새 항목이 생성되어 완전한 추적성과 재현성을 보장합니다.
-
검토하려는 워크플로 실행을 찾습니다. 각 실행은 상태 표시줄(예: 성공, 취소됨)과 함께 나열됩니다.
-
변환 구성을 보려면 실행 이름을 선택합니다.
-
로그 및 자세한 실행 결과를 보려면 상태 표시줄 아래의 로그를 선택합니다.
-
모델이 성공적으로 변환되면 메트릭 아래에서 평가 결과를 볼 수 있습니다. 정확도, 지연 시간 및 처리량과 같은 메트릭이 각 실행과 함께 표시됩니다.

-
작업 아래의 점 세 개 메뉴를 선택하여 변환된 모델과 상호 작용할 수 있습니다.
변환된 모델 경로 복사
- 드롭다운에서 모델 경로 복사를 선택합니다. 출력 변환된 모델 경로(예:
c:/{workspace}/{model_project}/history/{workflow}/model/model.onnx)가 참조를 위해 클립보드에 복사됩니다. LLM 모델의 경우 출력 폴더가 복사됩니다.
모델 추론을 위한 샘플 노트북 사용
- 드롭다운에서 샘플에서 추론을 선택합니다.
- Python 환경 선택
- Python 가상 환경을 선택하라는 메시지가 표시됩니다. 기본 런타임은 다음과 같습니다:
C:\Users\{user_name}\.aitk\bin\model_lab_runtime\Python-WCR-win32-x64-3.12.9. - 기본 런타임에는 필요한 모든 것이 포함되어 있습니다. 그렇지 않은 경우 requirements.txt를 수동으로 설치하세요.
- Python 가상 환경을 선택하라는 메시지가 표시됩니다. 기본 런타임은 다음과 같습니다:
- 샘플은 Jupyter Notebook에서 시작됩니다. 입력 데이터 또는 매개변수를 사용자 지정하여 다른 시나리오를 테스트할 수 있습니다.
클라우드 변환을 사용하는 모델의 경우 상태가 성공으로 변경된 후 클라우드 다운로드 아이콘을 선택하여 출력 모델을 로컬 머신으로 다운로드합니다. 
구성 또는 기록 관련 파일과 같은 기존 로컬 파일이 덮어쓰는 것을 방지하기 위해 누락된 파일만 다운로드됩니다. 깨끗한 복사본을 다운로드하려면 먼저 로컬 폴더를 삭제한 다음 다시 다운로드하세요.
모델 호환성: 변환된 모델이 추론 샘플에서 지정된 EP를 지원하는지 확인합니다.
샘플 위치: 추론 샘플은 기록 폴더의 실행 아티팩트와 함께 저장됩니다.
내보내기 및 다른 사람과 공유
기록 보드로 이동합니다. 내보내기를 선택하여 모델 프로젝트를 다른 사람과 공유합니다. 이렇게 하면 기록 폴더 없이 모델 프로젝트가 복사됩니다. 다른 사람과 모델을 공유하려면 해당 작업을 선택합니다. 이렇게 하면 모델 및 해당 구성이 포함된 선택한 기록 폴더가 복사됩니다.
학습 내용
이 문서에서는 다음 방법을 배웠습니다.
- VS Code의 AI Toolkit에서 모델 변환 프로젝트를 만듭니다.
- 양자화 및 평가 설정을 포함한 변환 워크플로를 구성합니다.
- 변환 워크플로를 실행하여 사전 구축된 모델을 최적화된 ONNX 모델로 변환합니다.
- 메트릭 및 로그를 포함한 변환 결과를 봅니다.
- 모델 추론 및 테스트를 위해 샘플 노트북을 사용합니다.
- 모델 프로젝트를 다른 사람과 내보내고 공유합니다.
- 다른 실행 공급자 또는 데이터 세트를 사용하여 모델을 다시 평가합니다.
- 실패한 작업을 처리하고 재실행을 위해 구성을 조정합니다.
- 변환 및 양자화를 위한 지원되는 모델 및 해당 요구 사항을 이해합니다.