모델, 프롬프트 및 에이전트 평가
모델, 프롬프트 및 에이전트는 출력을 기준 데이터와 비교하고 평가 메트릭을 계산하여 평가할 수 있습니다. AI Toolkit은 이 프로세스를 간소화합니다. 최소한의 노력으로 데이터 세트를 업로드하고 포괄적인 평가를 실행합니다.
프롬프트 및 에이전트 평가
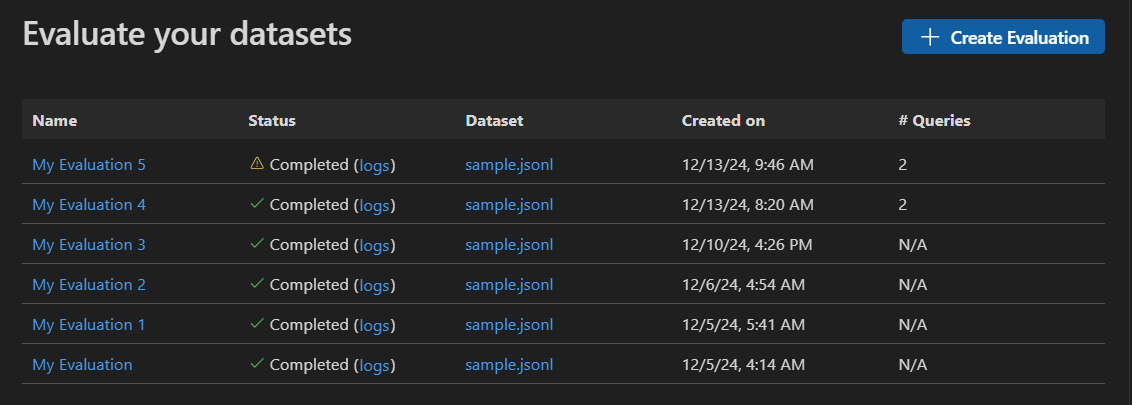
Agent Builder에서 Evaluation 탭을 선택하여 프롬프트 및 에이전트를 평가할 수 있습니다. 평가하기 전에 데이터 세트에 대해 프롬프트 또는 에이전트를 실행합니다. 데이터 세트 작업 방법을 알아보려면 Bulk run에 대해 더 알아보세요.
프롬프트 또는 에이전트를 평가하려면
- Agent Builder에서 Evaluation 탭을 선택합니다.
- 평가하려는 데이터 세트를 추가하고 실행합니다.
- 좋아요와 싫어요 아이콘을 사용하여 응답을 평가하고 수동 평가 기록을 유지합니다.
- 평가자를 추가하려면 New Evaluation을 선택합니다.
- F1 점수, 관련성, 일관성 또는 유사성과 같은 내장 평가자 목록에서 평가자를 선택합니다.참고
평가를 실행하기 위해 GitHub 호스팅 모델을 사용할 때 Rate limits가 적용될 수 있습니다.
- 필요한 경우 평가의 심사 모델로 사용할 모델을 선택합니다.
- Run Evaluation을 선택하여 평가 작업을 시작합니다.

버전 관리 및 평가 비교
AI Toolkit은 프롬프트 및 에이전트의 버전 관리를 지원하므로 다른 버전의 성능을 비교할 수 있습니다. 새 버전을 만들 때 평가를 실행하고 이전 버전과 결과를 비교할 수 있습니다.
프롬프트 또는 에이전트의 새 버전을 저장하려면
- Agent Builder에서 시스템 또는 사용자 프롬프트를 정의하고 변수 및 도구를 추가합니다.
- 에이전트를 실행하거나 Evaluate 탭으로 전환하고 평가할 데이터 세트를 추가합니다.
- 프롬프트 또는 에이전트에 만족하면 도구 모음에서 Save as New Version을 선택합니다.
- 선택적으로 버전 이름을 제공하고 Enter 키를 누릅니다.
버전 기록 보기
Agent Builder에서 프롬프트 또는 에이전트의 버전 기록을 볼 수 있습니다. 버전 기록은 각 버전에 대한 평가 결과를 포함한 모든 버전을 보여줍니다.
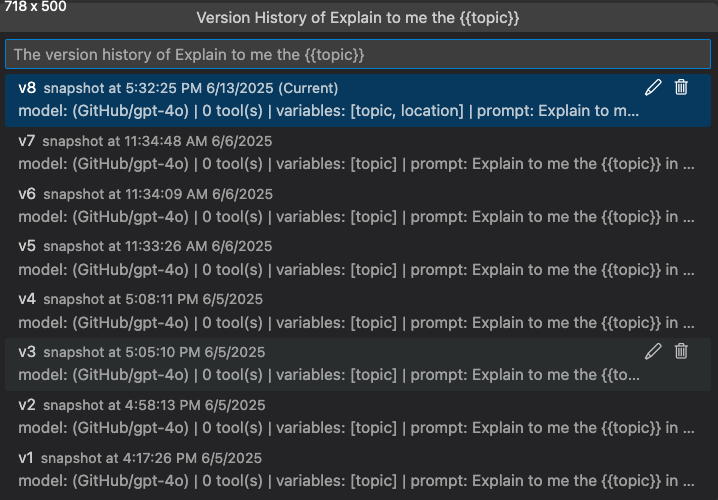
버전 기록 보기에서 다음을 수행할 수 있습니다.
- 버전 이름 옆의 연필 아이콘을 선택하여 버전을 다시 이름 지정합니다.
- 휴지통 아이콘을 선택하여 버전을 삭제합니다.
- 버전 이름을 선택하여 해당 버전으로 전환합니다.
버전 간 평가 결과 비교
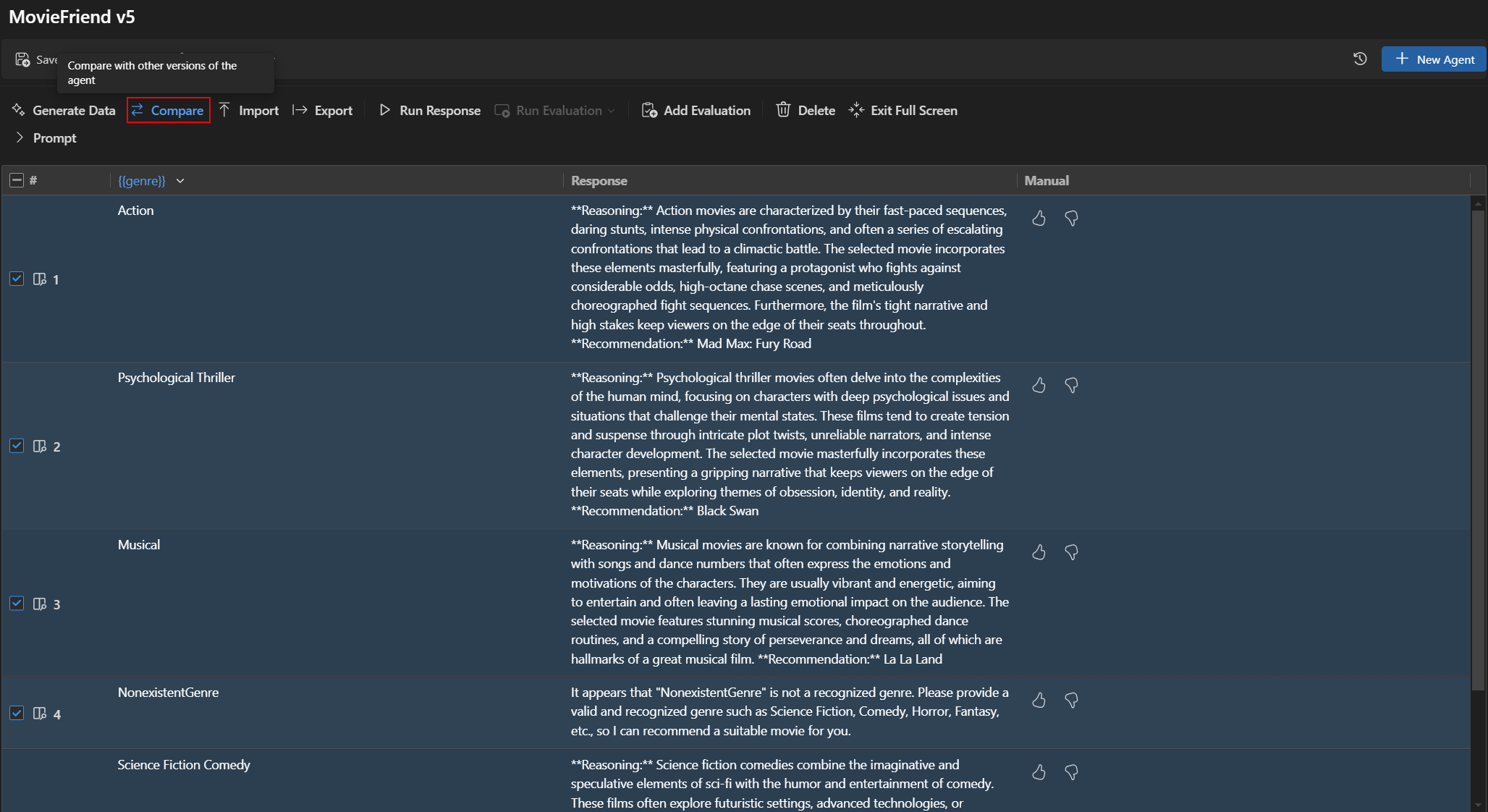
Agent Builder에서 다른 버전의 평가 결과를 비교할 수 있습니다. 결과는 각 평가자의 점수와 각 버전의 전체 점수를 보여주는 테이블로 표시됩니다.
버전 간 평가 결과를 비교하려면
- Agent Builder에서 Evaluation 탭을 선택합니다.
- 평가 도구 모음에서 Compare를 선택합니다.
- 비교하려는 버전을 목록에서 선택합니다.참고
비교 기능은 평가 결과의 가시성을 높이기 위해 Agent Builder의 전체 화면 모드에서만 사용할 수 있습니다. Prompt 섹션을 확장하여 모델 및 프롬프트 세부 정보를 볼 수 있습니다.
- 선택한 버전에 대한 평가 결과는 테이블로 표시되어 각 평가자의 점수와 각 버전의 전체 점수를 비교할 수 있습니다.
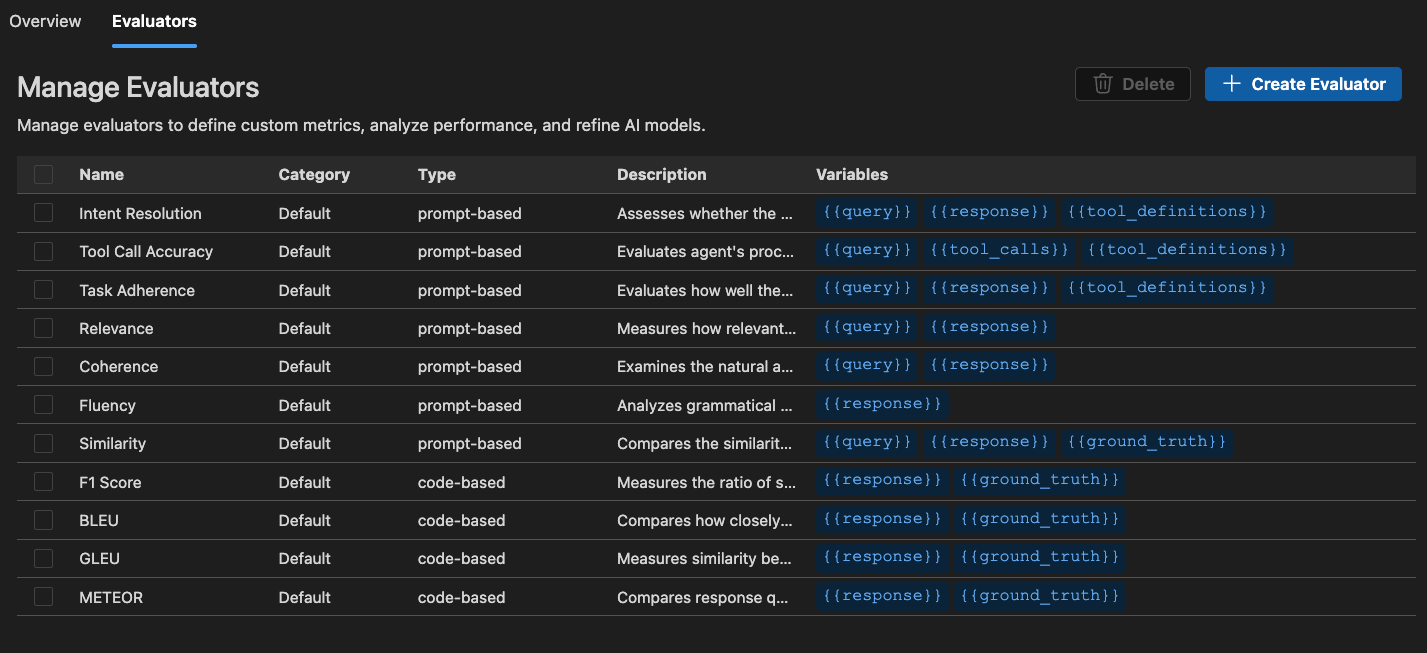
내장 평가자
AI Toolkit은 모델, 프롬프트 및 에이전트의 성능을 측정하기 위한 내장 평가자 세트를 제공합니다. 이러한 평가자는 모델 출력 및 기준 데이터에 따라 다양한 메트릭을 계산합니다.
에이전트의 경우
- Intent Resolution: 에이전트가 사용자 의도를 얼마나 정확하게 식별하고 해결하는지 측정합니다.
- Task Adherence: 에이전트가 식별된 작업을 얼마나 잘 이행하는지 측정합니다.
- Tool Call Accuracy: 에이전트가 올바른 도구를 얼마나 잘 선택하고 호출하는지 측정합니다.
일반 목적의 경우
- Coherence: 응답의 논리적 일관성과 흐름을 측정합니다.
- Fluency: 자연어 품질과 가독성을 측정합니다.
RAG (검색 증강 생성)의 경우
- Retrieval: 시스템이 관련 정보를 얼마나 효과적으로 검색하는지 측정합니다.
텍스트 유사성의 경우
- Similarity: AI 지원 텍스트 유사성 측정.
- F1 Score: 응답과 기준 데이터 간의 토큰 중복에서 정밀도와 재현율의 조화 평균입니다.
- BLEU: 번역 품질을 위한 Bilingual Evaluation Understudy 점수; 응답과 기준 데이터 간의 n-그램 중복을 측정합니다.
- GLEU: 문장 수준 평가를 위한 Google-BLEU 변형; 응답과 기준 데이터 간의 n-그램 중복을 측정합니다.
- METEOR: 명시적 순서가 있는 번역 평가 지표; 응답과 기준 데이터 간의 n-그램 중복을 측정합니다.
AI Toolkit의 평가자는 Azure Evaluation SDK를 기반으로 합니다. 생성 AI 모델의 관찰 가능성에 대해 자세히 알아보려면 Microsoft Foundry 설명서를 참조하세요.
독립 실행형 평가 작업 시작
-
AI Toolkit 보기에서 TOOLS > Evaluation을 선택하여 평가 보기로 이동합니다.
-
Create Evaluation을 선택한 다음 다음 정보를 제공합니다.
- Evaluation job name: 기본값을 사용하거나 사용자 지정 이름을 입력합니다.
- Evaluator: 내장 또는 사용자 지정 평가자 중에서 선택합니다.
- Judging model: 필요한 경우 심사 모델로 사용할 모델을 선택합니다.
- Dataset: 학습을 위한 샘플 데이터 세트를 선택하거나
query,response및ground truth필드가 있는 JSONL 파일을 가져옵니다.
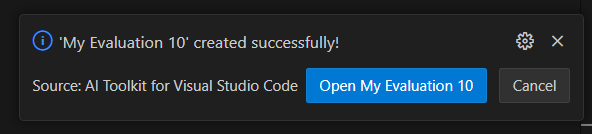
-
새 평가 작업이 생성됩니다. 평가 작업 세부 정보를 열 것이라는 메시지가 표시됩니다.
-
데이터 세트를 확인하고 Run Evaluation을 선택하여 평가를 시작합니다.
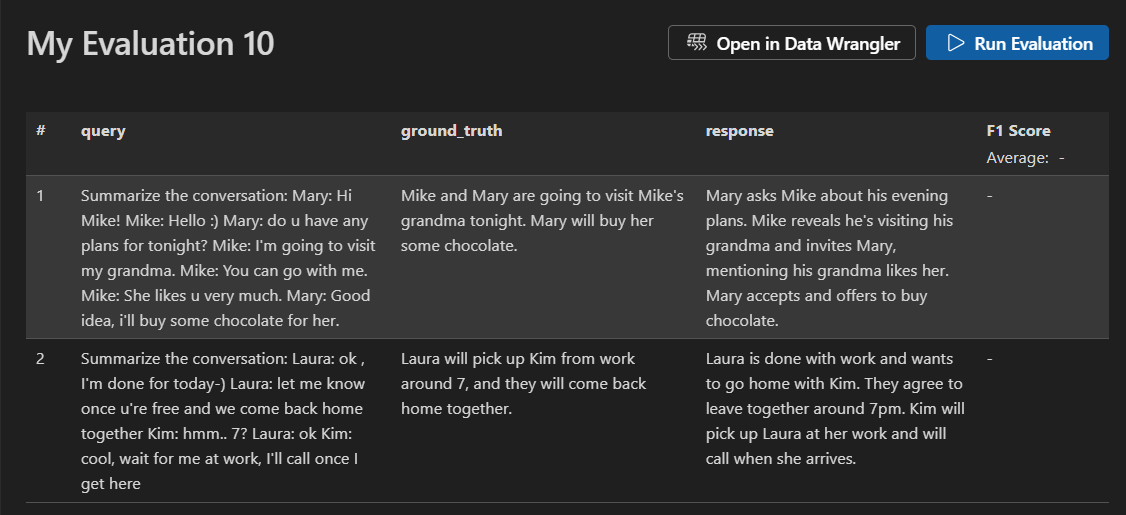
평가 작업 모니터링
평가 작업을 시작한 후 평가 작업 보기에서 상태를 볼 수 있습니다.

각 평가 작업에는 사용된 데이터 세트에 대한 링크, 평가 프로세스의 로그, 타임스탬프 및 평가 세부 정보에 대한 링크가 포함됩니다.
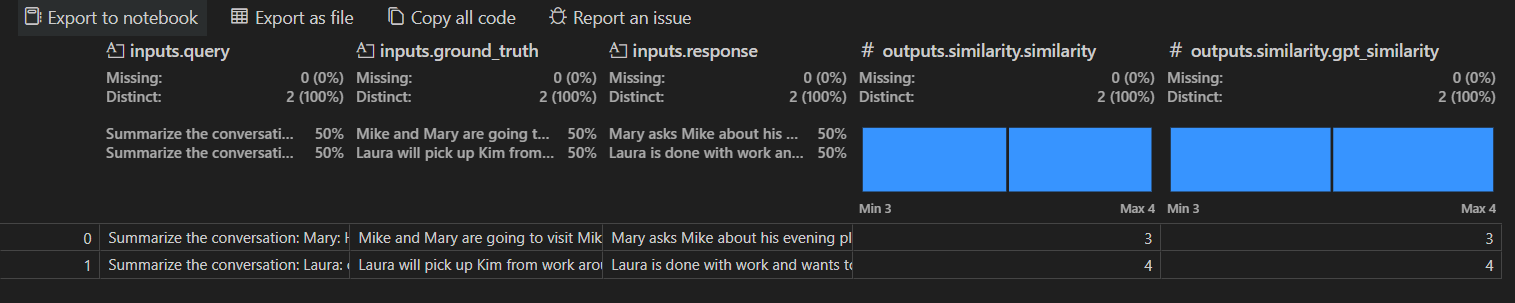
평가 결과 찾기
평가 작업 세부 정보 보기에는 선택한 각 평가자에 대한 결과 테이블이 표시됩니다. 일부 결과에는 집계 값이 포함될 수 있습니다.
Open In Data Wrangler를 선택하여 Data Wrangler 확장으로 데이터를 열 수도 있습니다.
사용자 지정 평가자 만들기
사용자 지정 평가자를 만들어 AI Toolkit의 내장 평가 기능을 확장할 수 있습니다. 사용자 지정 평가자를 사용하면 자체 평가 논리 및 메트릭을 정의할 수 있습니다.
사용자 지정 평가자를 만들려면
-
Evaluation 보기에서 Evaluators 탭을 선택합니다.
-
Create Evaluator를 선택하여 생성 양식을 엽니다.
-
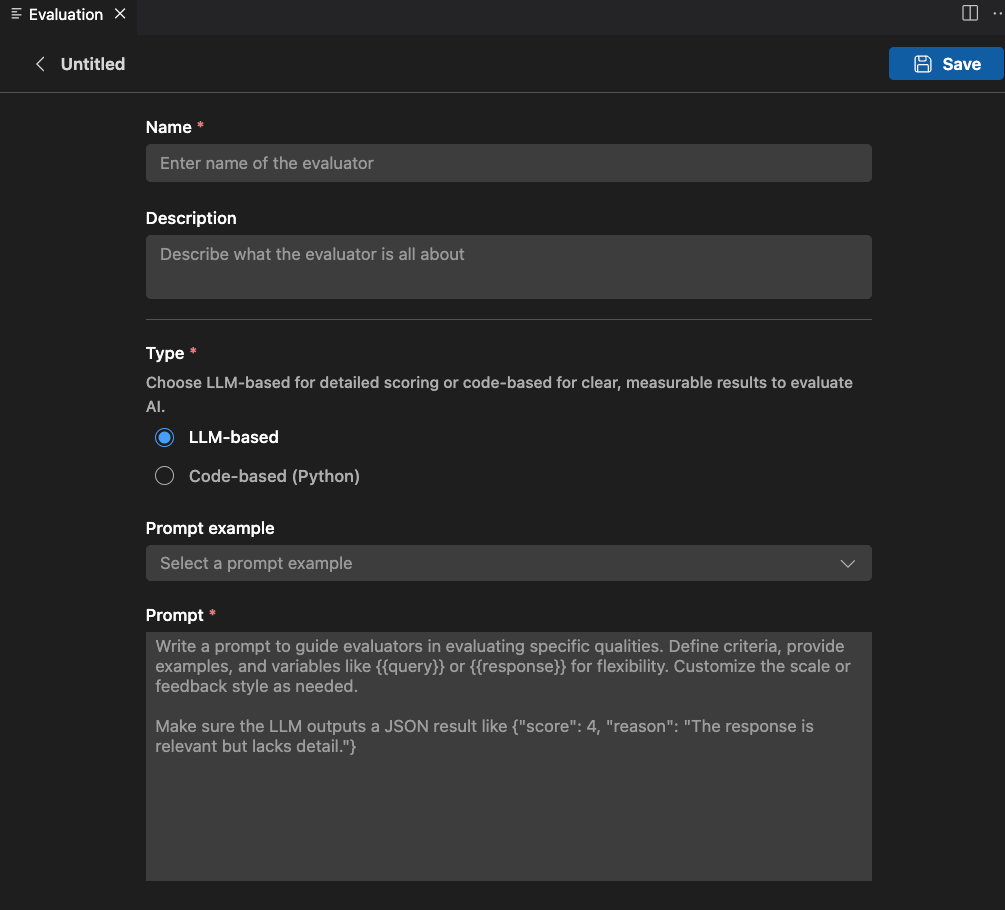
필요한 정보 제공
- Name: 사용자 지정 평가자의 이름을 입력합니다.
- Description: 평가자가 수행하는 작업을 설명합니다.
- Type: 평가자 유형을 선택합니다: LLM 기반 또는 코드 기반(Python).
-
선택한 유형에 대한 지침을 따라 설정을 완료합니다.
-
Save를 선택하여 사용자 지정 평가자를 만듭니다.
-
사용자 지정 평가자를 만든 후 새 평가 작업을 만들 때 선택할 수 있는 평가자 목록에 나타납니다.
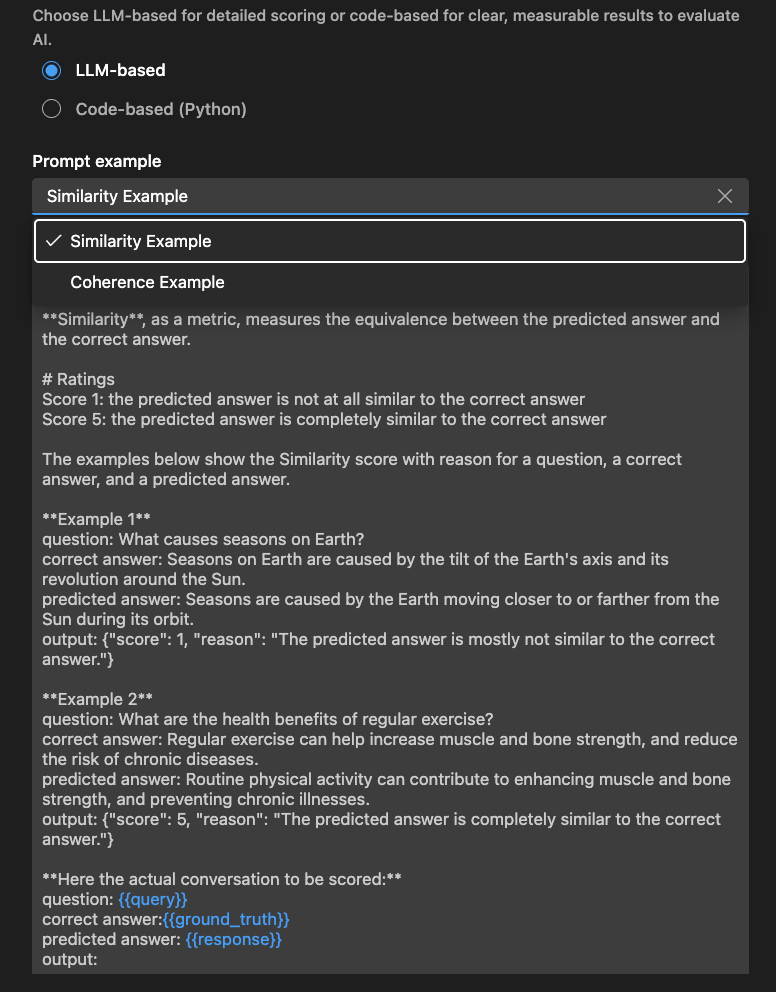
LLM 기반 평가자
LLM 기반 평가자의 경우 자연어 프롬프트를 사용하여 평가 논리를 정의합니다.
특정 품질을 평가하는 데 평가자를 안내하는 프롬프트를 작성합니다. 기준을 정의하고, 예제를 제공하고, 유연성을 위해 또는 와 같은 변수를 사용합니다. 필요한 경우 척도 또는 피드백 스타일을 사용자 지정합니다.
LLM이 JSON 결과(예: {"score": 4, "reason": "The response is relevant but lacks detail."})를 출력하는지 확인합니다.
Examples 섹션을 사용하여 LLM 기반 평가자를 시작할 수도 있습니다.
코드 기반 평가자
코드 기반 평가자의 경우 Python 코드를 사용하여 평가 논리를 정의합니다. 코드는 평가 점수 및 이유가 포함된 JSON 결과를 반환해야 합니다.
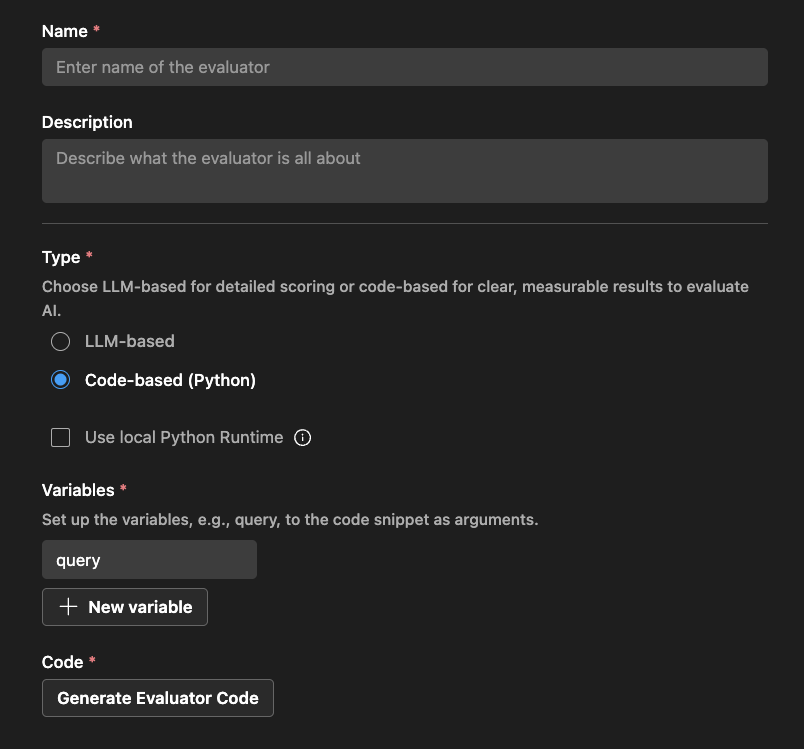
AI Toolkit은 평가자 이름과 외부 라이브러리 사용 여부에 따라 스캐폴드를 제공합니다.
코드를 수정하여 평가 논리를 구현할 수 있습니다.
# The method signature is generated automatically. Do not change it.
# Create a new evaluator if you want to change the method signature or arguments.
def measure_the_response_if_human_like_or_not(query, **kwargs):
# Add your evaluator logic to calculate the score.
# Return an object with score and an optional string message to display in the result.
return {
"score": 3,
"reason": "This is a placeholder for the evaluator's reason."
}
학습 내용
이 문서에서는 다음 방법을 배웠습니다.
- VS Code용 AI Toolkit에서 평가 작업을 만들고 실행합니다.
- 평가 작업 상태를 모니터링하고 결과를 확인합니다.
- 프롬프트 및 에이전트의 다른 버전에 대한 평가 결과 비교
- 프롬프트 및 에이전트의 버전 기록 보기
- 내장 평가자를 사용하여 다양한 메트릭으로 성능 측정
- 사용자 지정 평가자를 만들어 내장 평가 기능 확장
- LLM 기반 및 코드 기반 평가자를 사용하여 다양한 평가 시나리오에 적용