VS Code에서 Data Wrangler 시작하기
Data Wrangler는 VS Code 및 VS Code Jupyter Notebook에 통합된 코드 중심 데이터 보기 및 정리 도구입니다. 데이터를 보고 분석할 수 있는 풍부한 사용자 인터페이스를 제공하며, 통찰력 있는 열 통계 및 시각화를 표시하고 데이터를 정리하고 변환하는 동안 Pandas 코드를 자동으로 생성합니다.
다음은 Notebook에서 Data Wrangler를 열어 내장된 작업을 사용하여 데이터를 분석하고 정리하는 예시입니다. 그런 다음 자동으로 생성된 코드를 Notebook으로 다시 내보냅니다.

이 문서에서는 다음을 다룹니다.
- Data Wrangler 설치 및 설정
- Notebook에서 Data Wrangler 시작
- 데이터 파일에서 Data Wrangler 시작
- Data Wrangler를 사용하여 데이터 탐색
- Data Wrangler를 사용하여 데이터에 대한 작업 및 정리 수행
- 데이터 랭글링 코드를 Notebook으로 편집 및 내보내기
- 문제 해결 및 피드백 제공
환경 설정
- 아직 설치하지 않았다면 Python을 설치하세요. **중요:** Data Wrangler는 Python 버전 3.8 이상만 지원합니다.
- Visual Studio Code를 설치합니다.
- Data Wrangler 확장 설치
Data Wrangler를 처음 실행하면 연결할 Python 커널을 묻는 메시지가 표시됩니다. 또한 컴퓨터와 환경을 확인하여 Pandas와 같은 필수 Python 패키지가 설치되어 있는지 확인합니다.
다음은 Python 및 Python 패키스의 필수 버전 목록과 Data Wrangler에서 자동으로 설치되는지 여부입니다.
| 이름 | 최소 필수 버전 | 자동 설치됨 |
|---|---|---|
| Python | 3.8 | 아니요 |
| pandas | 0.25.2 | 예 |
이러한 종속성이 환경에 없는 경우 Data Wrangler가 pip를 사용하여 설치를 시도합니다. Data Wrangler가 종속성을 설치할 수 없는 경우 가장 쉬운 해결 방법은 pip install을 수동으로 실행한 다음 Data Wrangler를 다시 시작하는 것입니다. 이러한 종속성은 Data Wrangler가 Python 및 Pandas 코드를 생성할 수 있도록 하는 데 필수적입니다.
Data Wrangler 열기
Data Wrangler에 있는 동안에는 항상 *샌드박스* 환경에 있으므로 데이터를 안전하게 탐색하고 변환할 수 있습니다. 변경 사항을 명시적으로 내보내기 전까지는 원본 데이터 세트가 수정되지 않습니다.
Jupyter Notebook에서 Data Wrangler 시작
Jupyter Notebook에서 Data Wrangler를 시작하는 세 가지 방법이 있습니다.

- Jupyter > Variables 패널에서 지원되는 데이터 개체 옆에 Data Wrangler를 시작하는 버튼이 표시됩니다.
- Notebook에 Pandas 데이터 프레임이 있는 경우 데이터 프레임을 출력하는 코드를 실행한 후 셀 하단에 'df'를 Data Wrangler에서 열기 버튼(여기서 'df'는 데이터 프레임의 변수 이름)이 나타납니다. 여기에는 1)
df.head(), 2)df.tail(), 3)display(df), 4)print(df), 5)df가 포함됩니다. - Notebook 도구 모음에서 데이터 보기를 선택하면 Notebook에 있는 모든 지원되는 데이터 개체 목록이 표시됩니다. 그런 다음 해당 목록에서 Data Wrangler에서 열고 싶은 변수를 선택할 수 있습니다.
파일에서 직접 Data Wrangler 시작
로컬 파일(예: .csv)에서 직접 Data Wrangler를 시작할 수도 있습니다. 이를 위해 열려는 파일이 포함된 폴더를 VS Code에서 엽니다. 파일 탐색기 보기에서 파일을 마우스 오른쪽 버튼으로 클릭하고 Data Wrangler에서 열기를 클릭합니다.
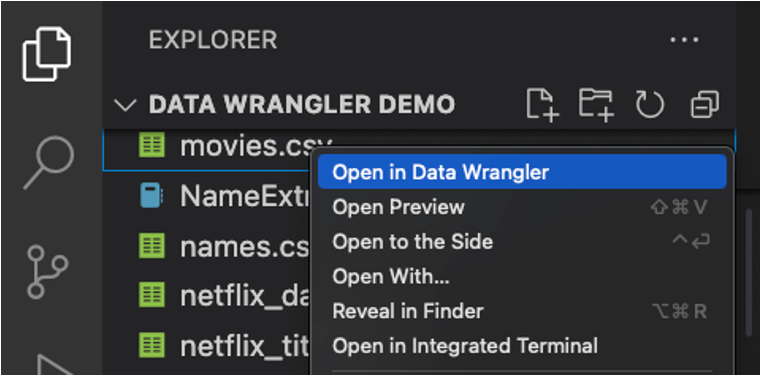
Data Wrangler는 현재 다음 파일 형식을 지원합니다.
.csv/.tsv.xls/.xlsx.parquet
파일 형식에 따라 구분 기호 및/또는 파일 시트를 지정할 수 있습니다.
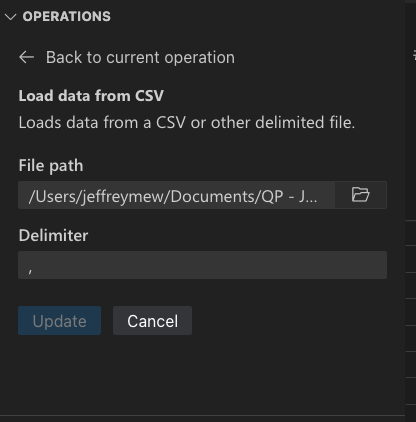
기본적으로 Data Wrangler에서 열도록 이러한 파일 형식을 설정할 수도 있습니다.
UI 둘러보기
Data Wrangler에는 데이터를 다루는 두 가지 모드가 있습니다. 각 모드에 대한 자세한 내용은 아래 후속 섹션에서 설명합니다.
- 보기 모드: 보기 모드는 데이터를 빠르게 보고, 필터링하고, 정렬하도록 인터페이스를 최적화합니다. 이 모드는 데이터 세트에 대한 초기 탐색을 수행하는 데 탁월합니다.
- 편집 모드: 편집 모드는 데이터 세트에 변환, 정리 또는 수정을 적용하도록 인터페이스를 최적화합니다. 인터페이스에서 이러한 변환을 적용하면 Data Wrangler가 관련 Pandas 코드를 자동으로 생성하며, 이 코드는 재사용을 위해 Notebook으로 다시 내보낼 수 있습니다.
참고: 기본적으로 Data Wrangler는 보기 모드로 열립니다. 이 동작은 설정 편집기 에서 변경할 수 있습니다.

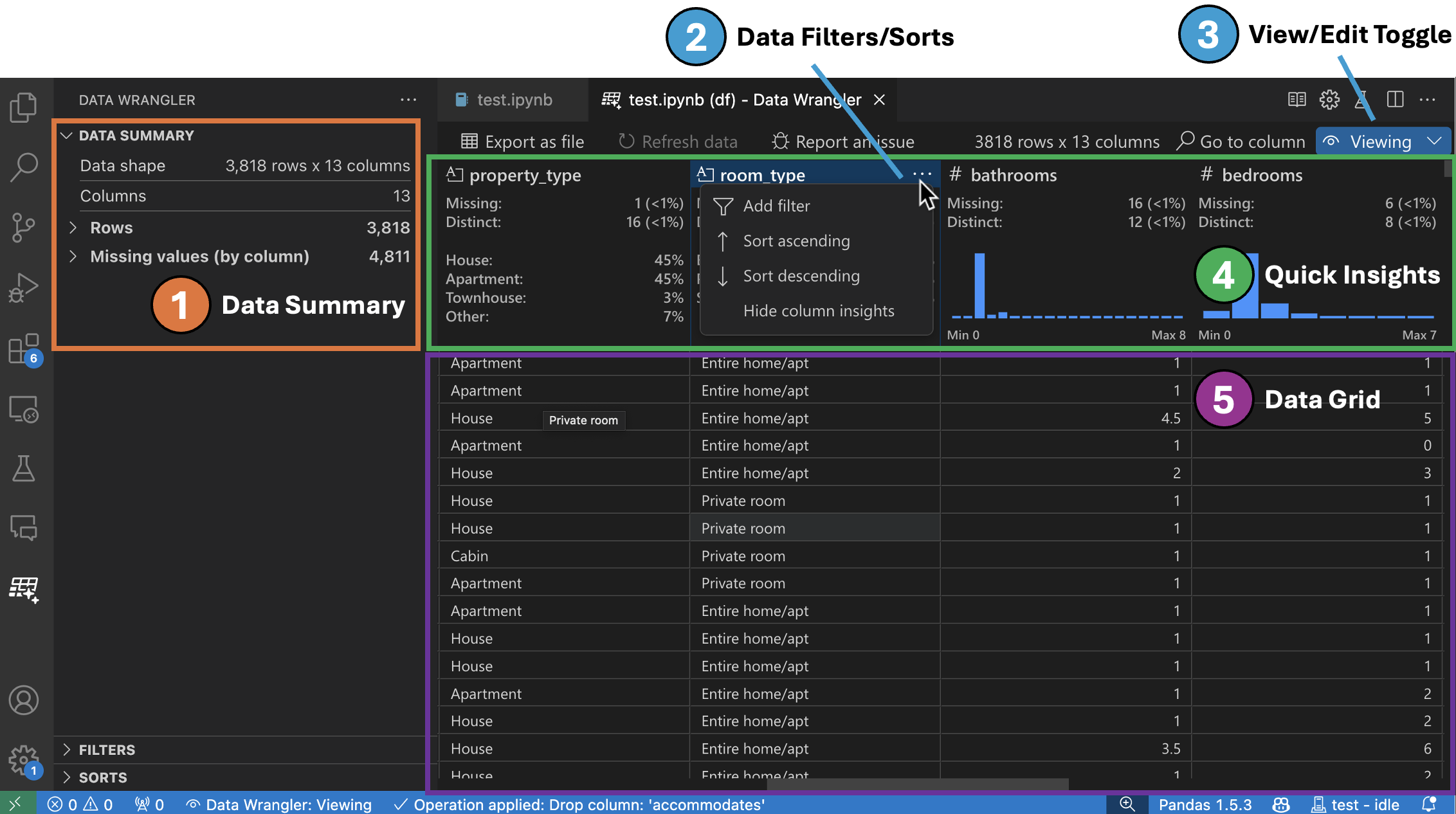
보기 모드 인터페이스
-
데이터 요약 패널은 전체 데이터 세트 또는 특정 열(선택한 경우)에 대한 자세한 요약 통계를 표시합니다.
-
열 헤더 메뉴에서 열에 대한 모든 데이터 필터/정렬을 적용할 수 있습니다.
-
Data Wrangler의 보기 또는 편집 모드를 전환하여 내장 데이터 작업에 액세스합니다.
-
빠른 통찰력 헤더는 각 열에 대한 유용한 정보를 빠르게 볼 수 있는 곳입니다. 열의 데이터 유형에 따라 빠른 통찰력은 데이터의 분포 또는 데이터 포인트의 빈도, 누락된 값 및 고유한 값을 표시합니다.
-
데이터 그리드는 전체 데이터 세트를 볼 수 있는 스크롤 가능한 창을 제공합니다.
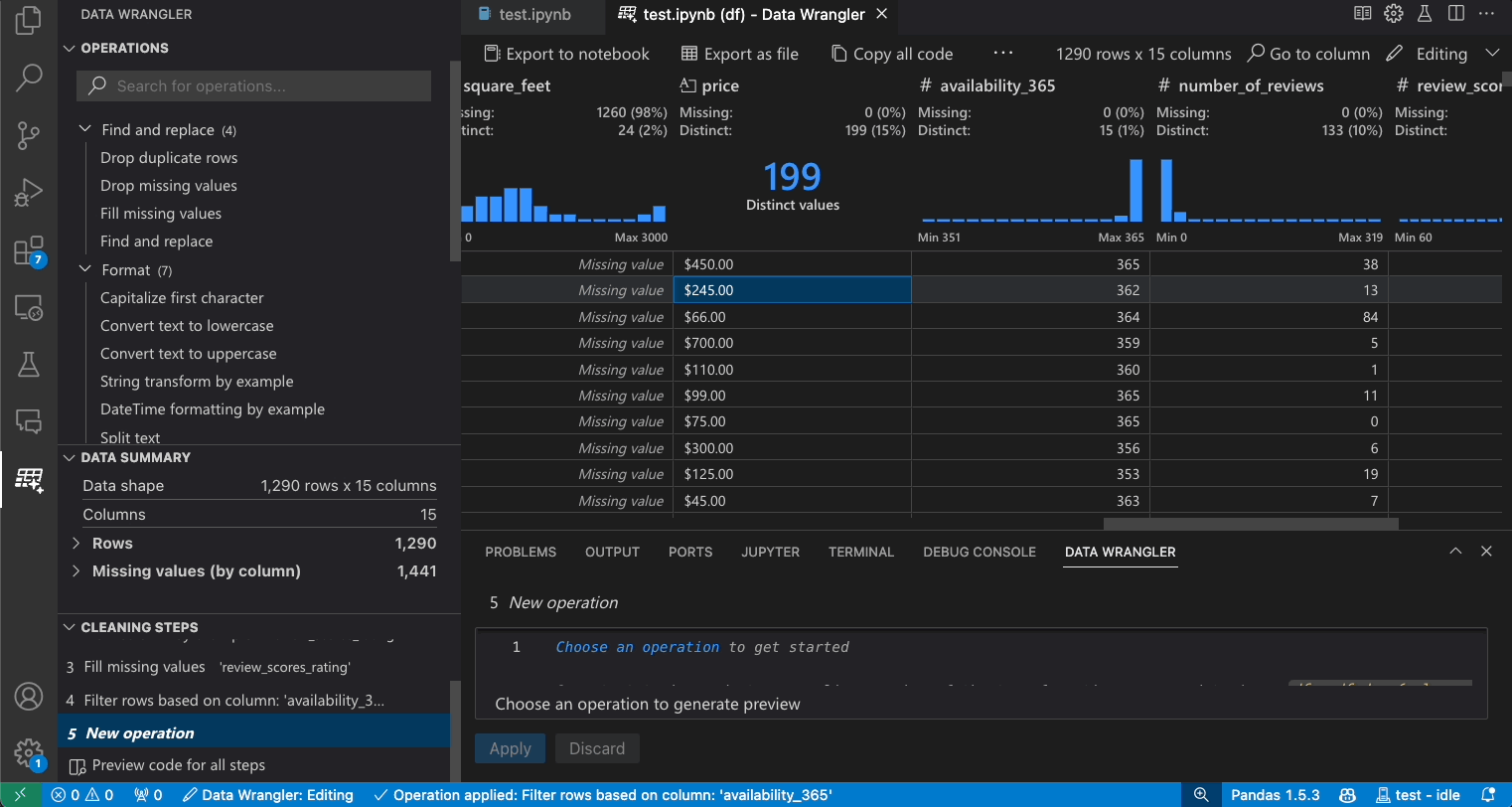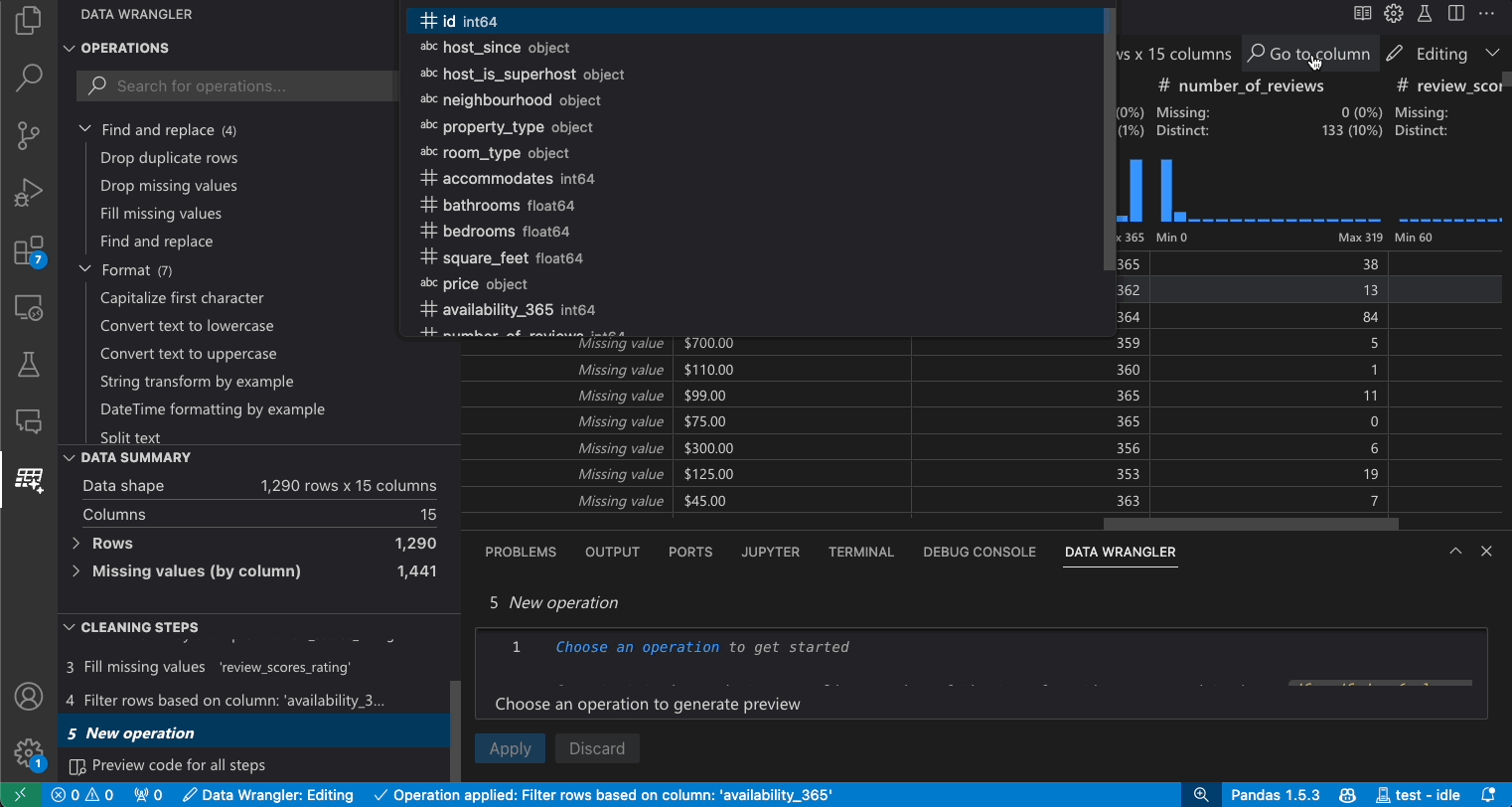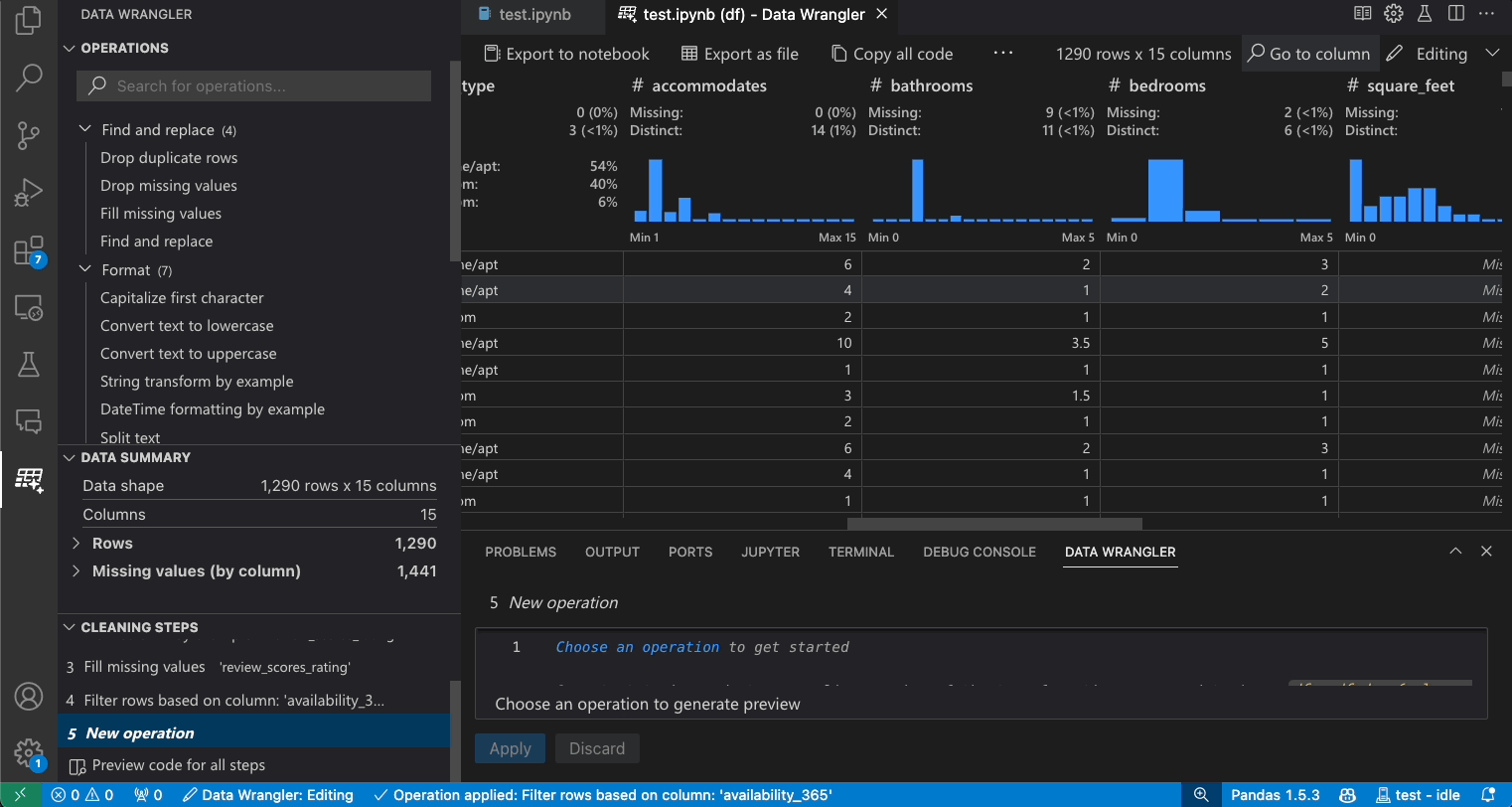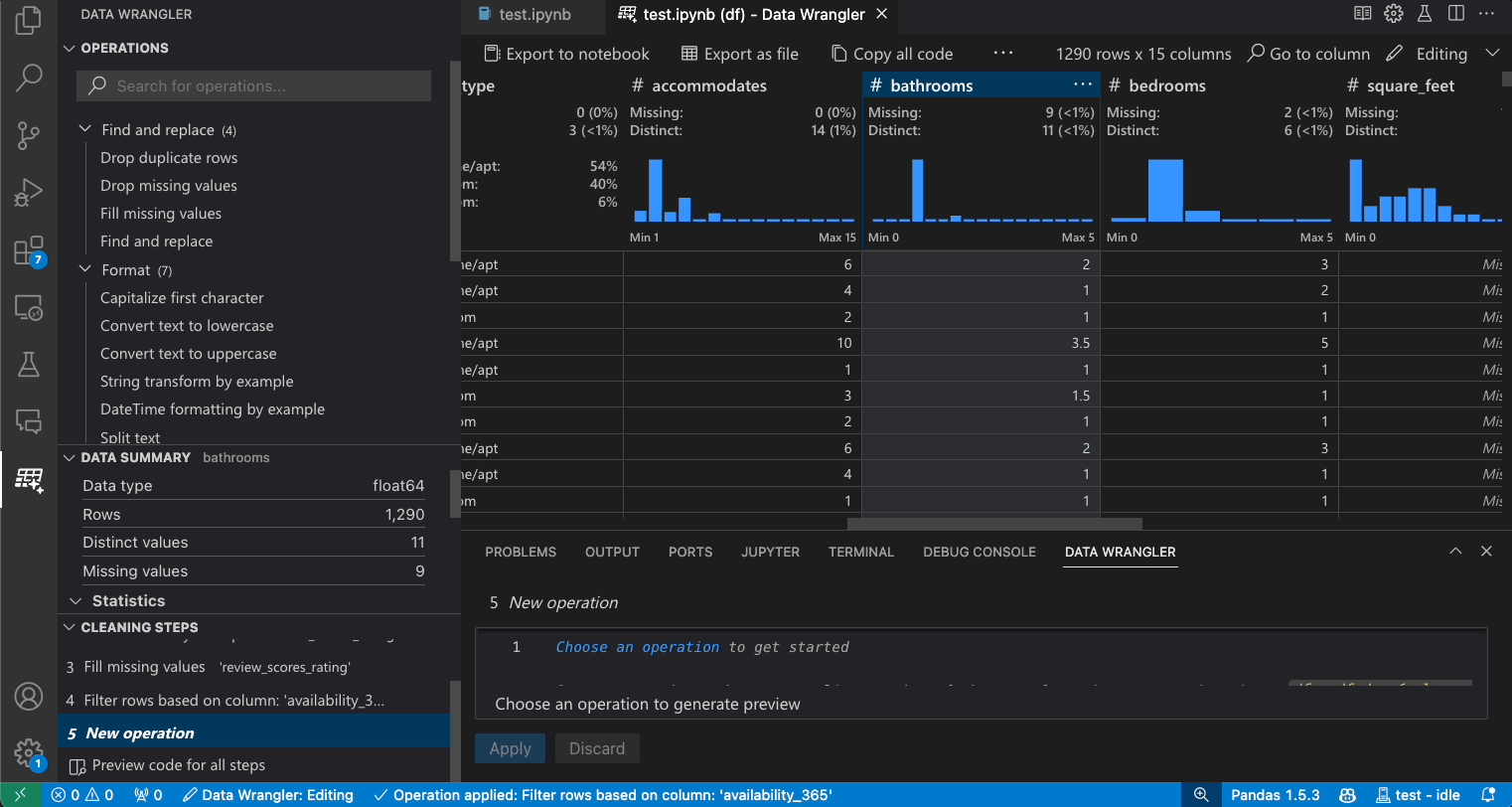
편집 모드 인터페이스
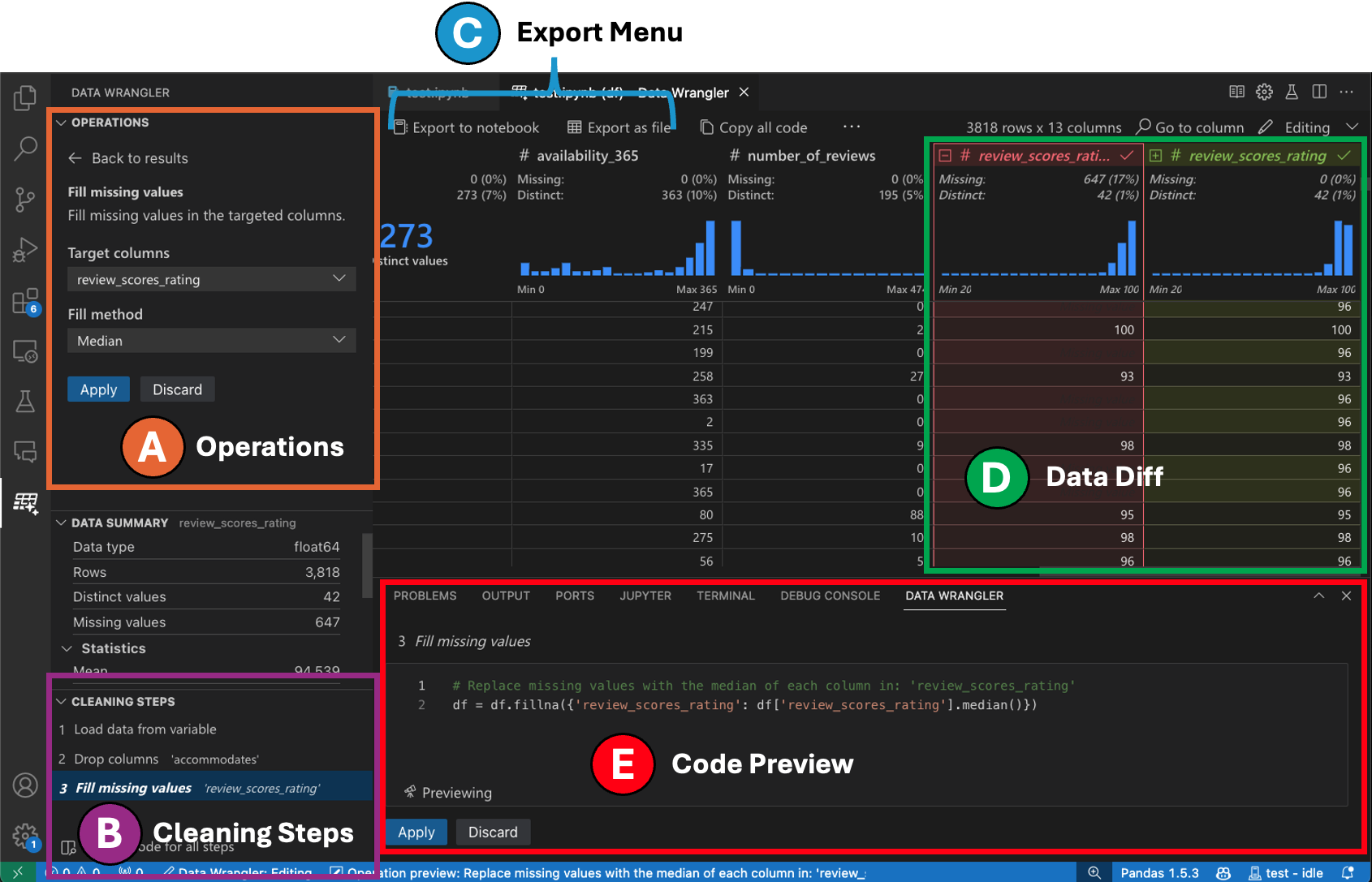
편집 모드로 전환하면 Data Wrangler에서 추가 기능과 사용자 인터페이스 요소가 활성화됩니다. 다음 스크린샷에서는 Data Wrangler를 사용하여 마지막 열의 누락된 값을 해당 열의 중앙값으로 바꿉니다.
-
작업 패널은 Data Wrangler의 모든 내장 데이터 작업을 검색할 수 있는 곳입니다. 작업은 범주별로 구성됩니다.
-
정리 단계 패널에는 이전에 적용된 모든 작업 목록이 표시됩니다. 사용자는 특정 작업을 실행 취소하거나 *가장 최근* 작업을 편집할 수 있습니다. 단계를 선택하면 데이터 차이 보기에서 변경 사항이 강조 표시되고 해당 작업과 관련된 생성된 코드가 표시됩니다.
-
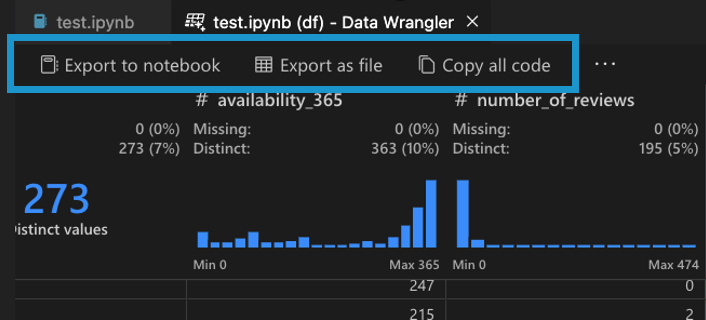
내보내기 메뉴를 사용하면 코드를 Jupyter Notebook으로 다시 내보내거나 데이터를 새 파일로 내보낼 수 있습니다.
-
작업을 선택하고 데이터에 대한 영향을 미리 볼 때 그리드에는 수행한 변경 사항의 **데이터 차이** 보기가 오버레이됩니다.
-
코드 미리 보기 섹션에는 작업이 선택될 때 Data Wrangler가 생성한 Python 및 Pandas 코드가 표시됩니다. 작업이 선택되지 않았을 때는 비어 있습니다. 생성된 코드를 편집할 수 있으며, 이로 인해 데이터 그리드에 데이터에 미치는 영향이 강조 표시됩니다.
Data Wrangler 작업
내장 Data Wrangler 작업은 작업 패널에서 선택할 수 있습니다.
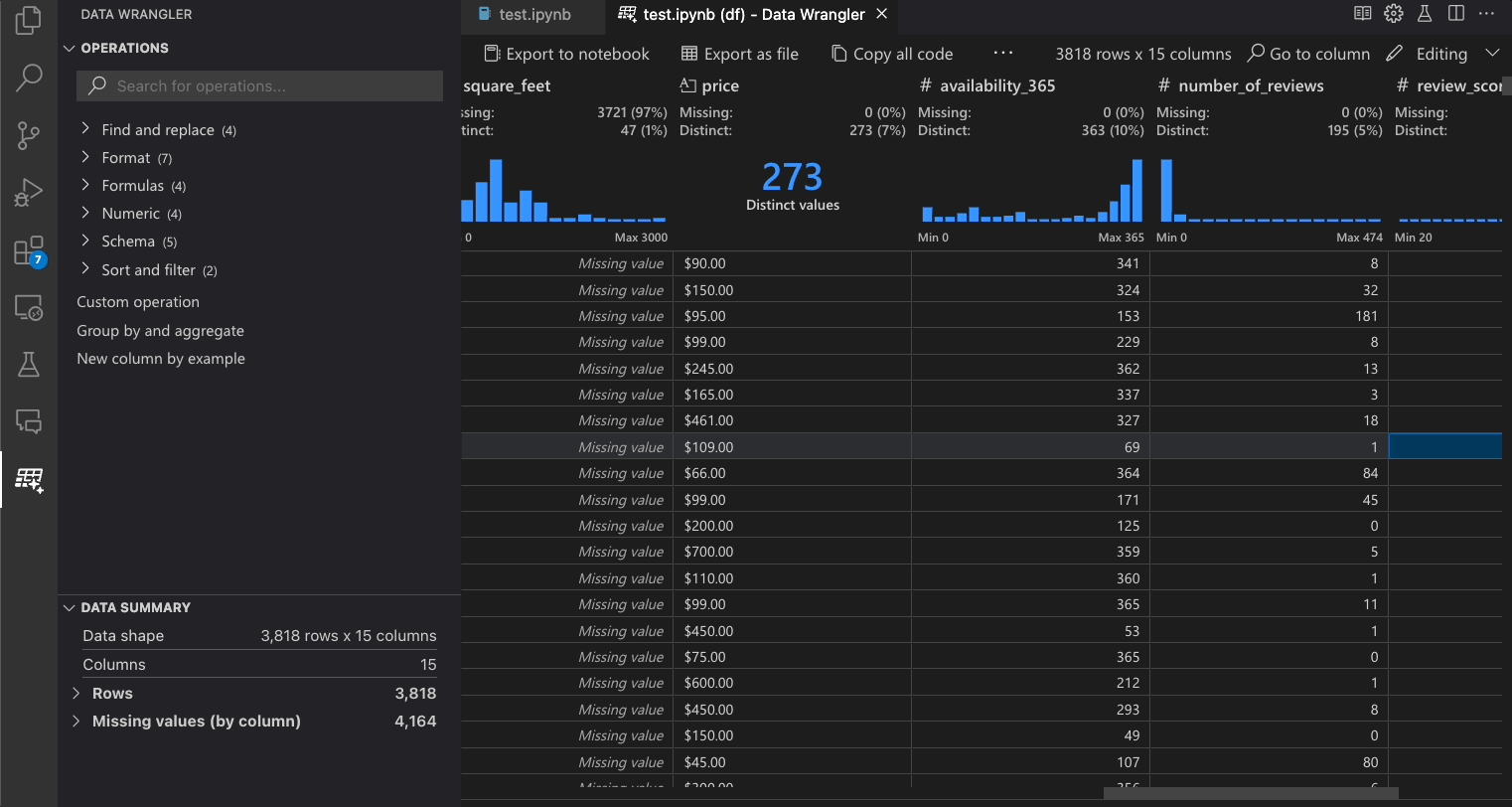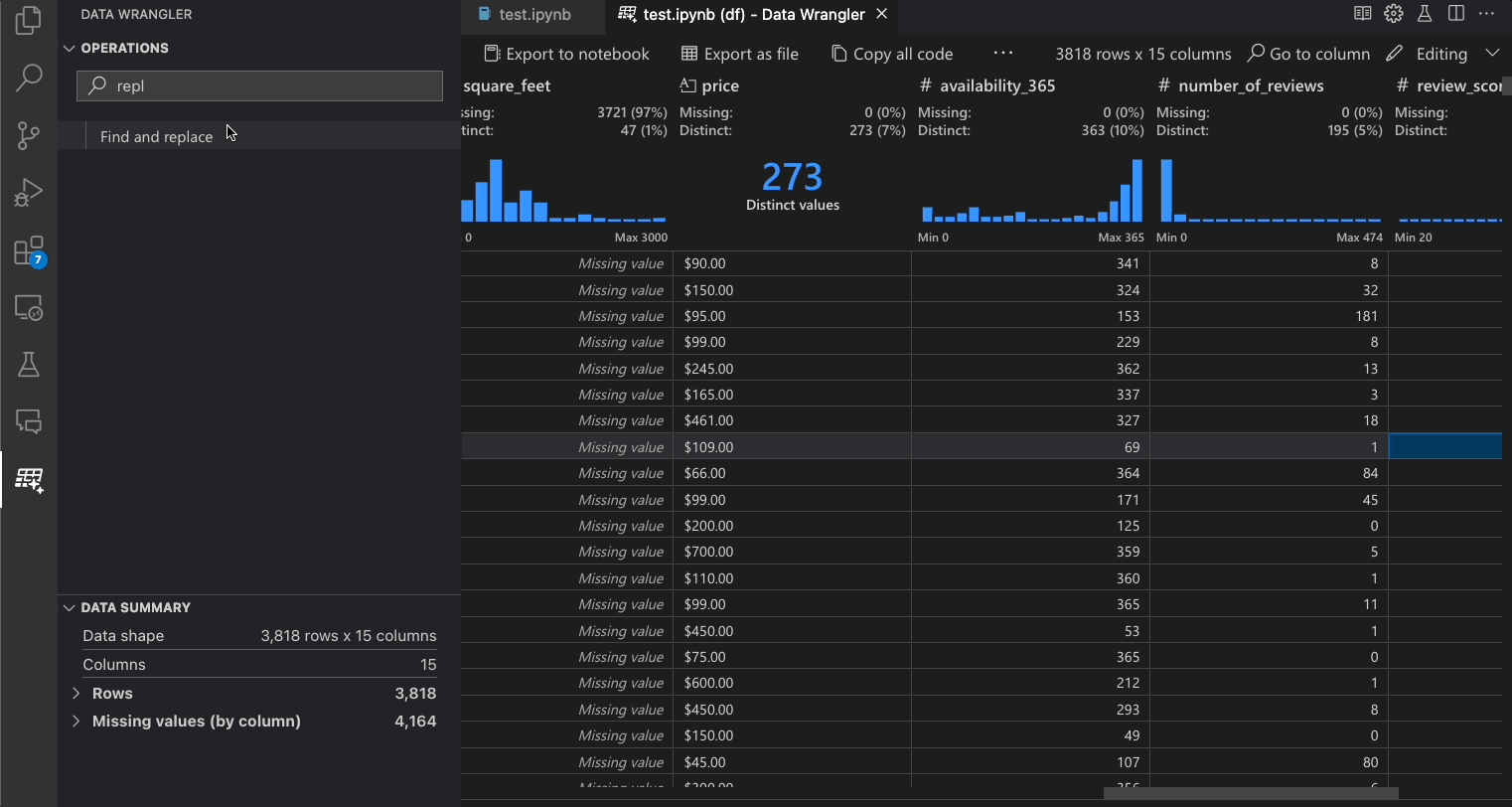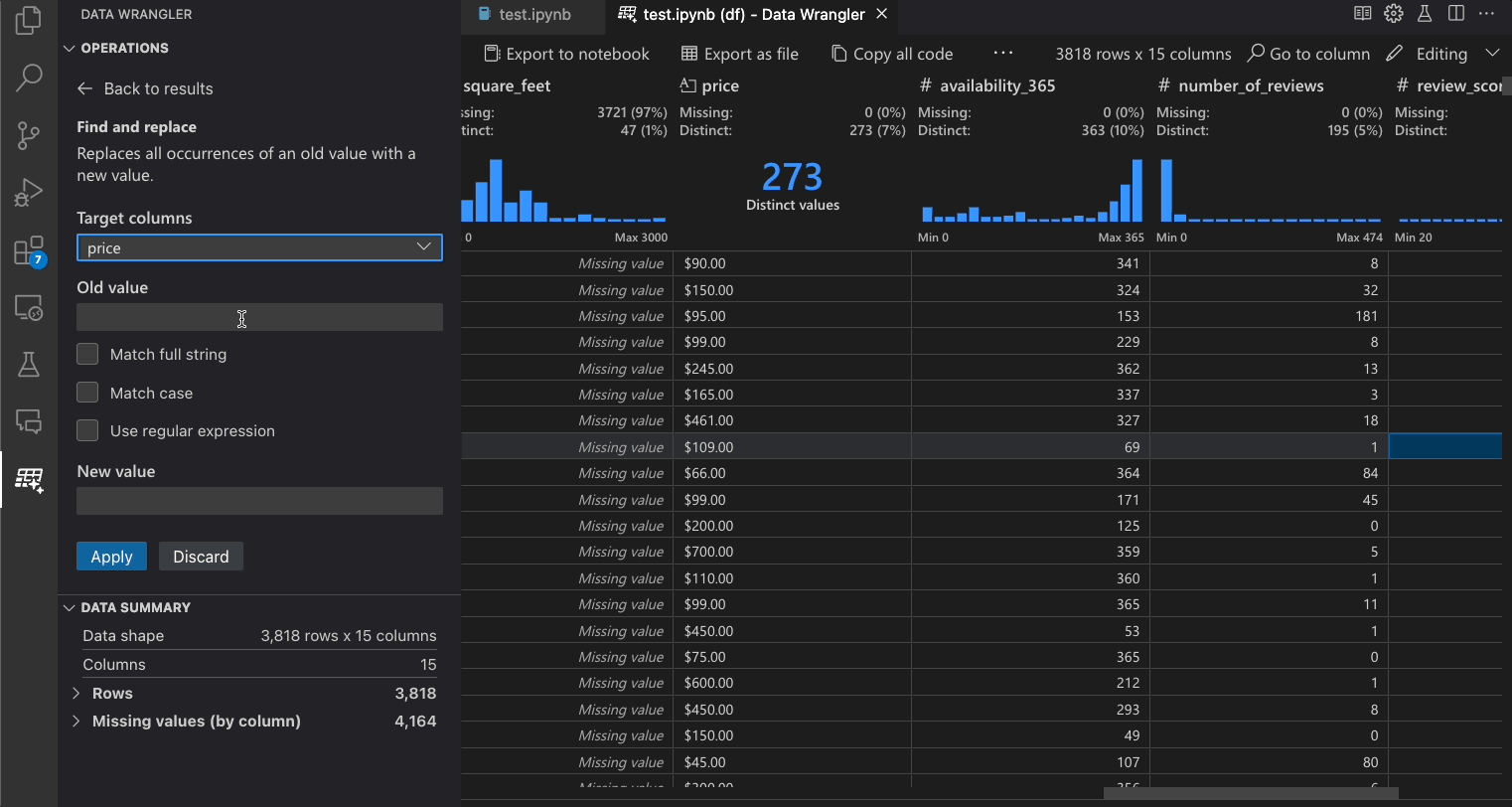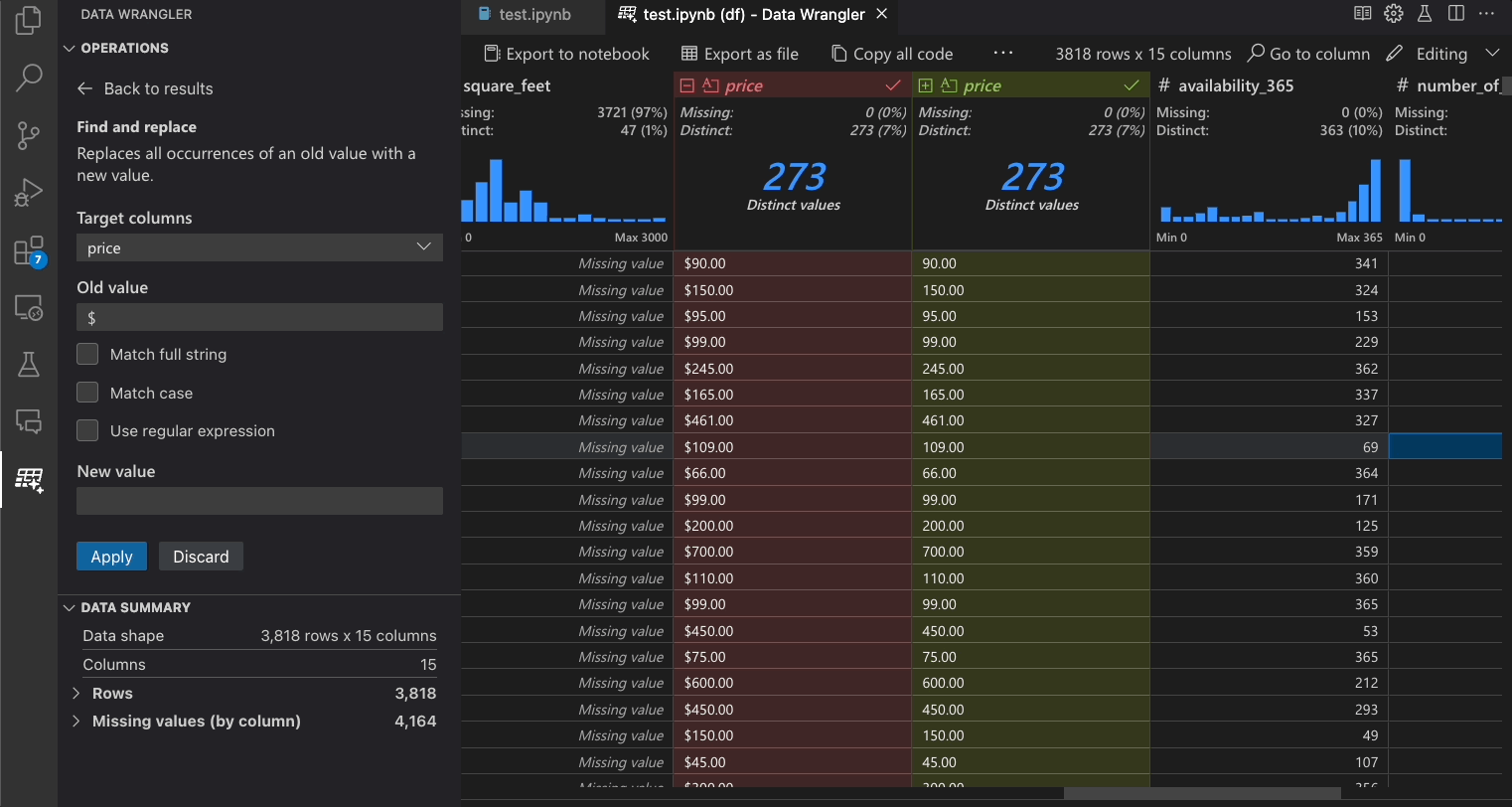
다음 표는 Data Wrangler의 초기 릴리스에서 현재 지원되는 Data Wrangler 작업 목록입니다. 가까운 시일 내에 더 많은 작업을 추가할 계획입니다.
| 작업 | 설명 |
|---|---|
| 정렬 | 열을 오름차순 또는 내림차순으로 정렬 |
| 필터 | 하나 이상의 조건에 따라 행 필터링 |
| 텍스트 길이 계산 | 텍스트 열의 각 문자열 값의 길이에 해당하는 값을 가진 새 열 생성 |
| 원-핫 인코딩 | 범주형 데이터를 각 범주에 대한 새 열로 분할 |
| 다중 레이블 이진화 | 구분 기호를 사용하여 범주형 데이터를 각 범주에 대한 새 열로 분할 |
| 수식으로 열 만들기 | 사용자 지정 Python 수식을 사용하여 열 만들기 |
| 열 유형 변경 | 열의 데이터 유형 변경 |
| 열 삭제 | 하나 이상의 열 삭제 |
| 열 선택 | 유지할 하나 이상의 열을 선택하고 나머지는 삭제 |
| 열 이름 변경 | 하나 이상의 열 이름 변경 |
| 열 복제 | 하나 이상의 열 복사본 만들기 |
| 누락된 값 삭제 | 누락된 값이 있는 행 제거 |
| 중복 행 삭제 | 하나 이상의 열에서 중복 값이 있는 모든 행 삭제 |
| 누락된 값 채우기 | 새 값으로 누락된 값이 있는 셀 바꾸기 |
| 찾기 및 바꾸기 | 일치하는 패턴이 있는 셀 바꾸기 |
| 열별 그룹화 및 집계 | 열별로 그룹화하고 결과 집계 |
| 공백 제거 | 텍스트의 시작 및 끝 공백 제거 |
| 텍스트 분할 | 사용자 정의 구분 기호를 기반으로 열을 여러 열로 분할 |
| 첫 글자 대문자 | 첫 글자를 대문자로, 나머지는 소문자로 변환 |
| 텍스트를 소문자로 변환 | 텍스트를 소문자로 변환 |
| 텍스트를 대문자로 변환 | 텍스트를 대문자로 변환 |
| 예시별 문자열 변환 | 제공한 예에서 패턴이 감지될 때 문자열 변환 자동 수행 |
| 예시별 DateTime 형식 지정 | 제공한 예에서 패턴이 감지될 때 DateTime 형식 지정 자동 수행 |
| 예시별 새 열 | 제공한 예에서 패턴이 감지될 때 열 자동 생성. |
| 최소/최대 값 스케일링 | 최소값과 최대값 사이의 숫자 열 스케일링 |
| 반올림 | 지정된 소수 자릿수로 숫자 반올림 |
| 내림(바닥) | 가장 가까운 정수로 숫자를 내림 |
| 올림(천장) | 가장 가까운 정수로 숫자를 올림 |
| 사용자 지정 작업 | 예시 및 기존 열의 파생을 기반으로 새 열 자동 만들기 |
Data Wrangler에서 지원되기를 바라는 작업이 누락되었다면, Data Wrangler GitHub 저장소에 기능 요청을 제출해 주세요.
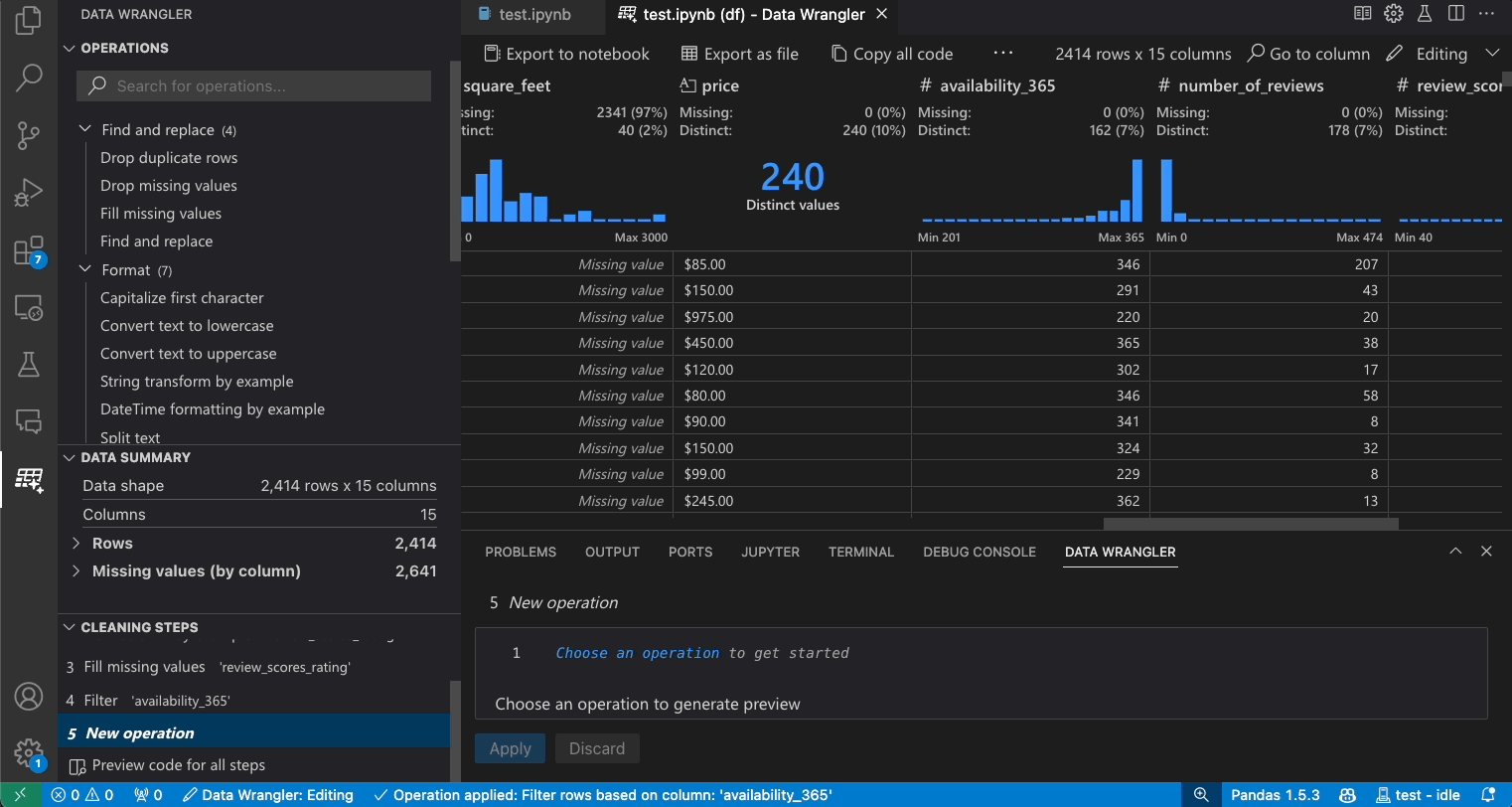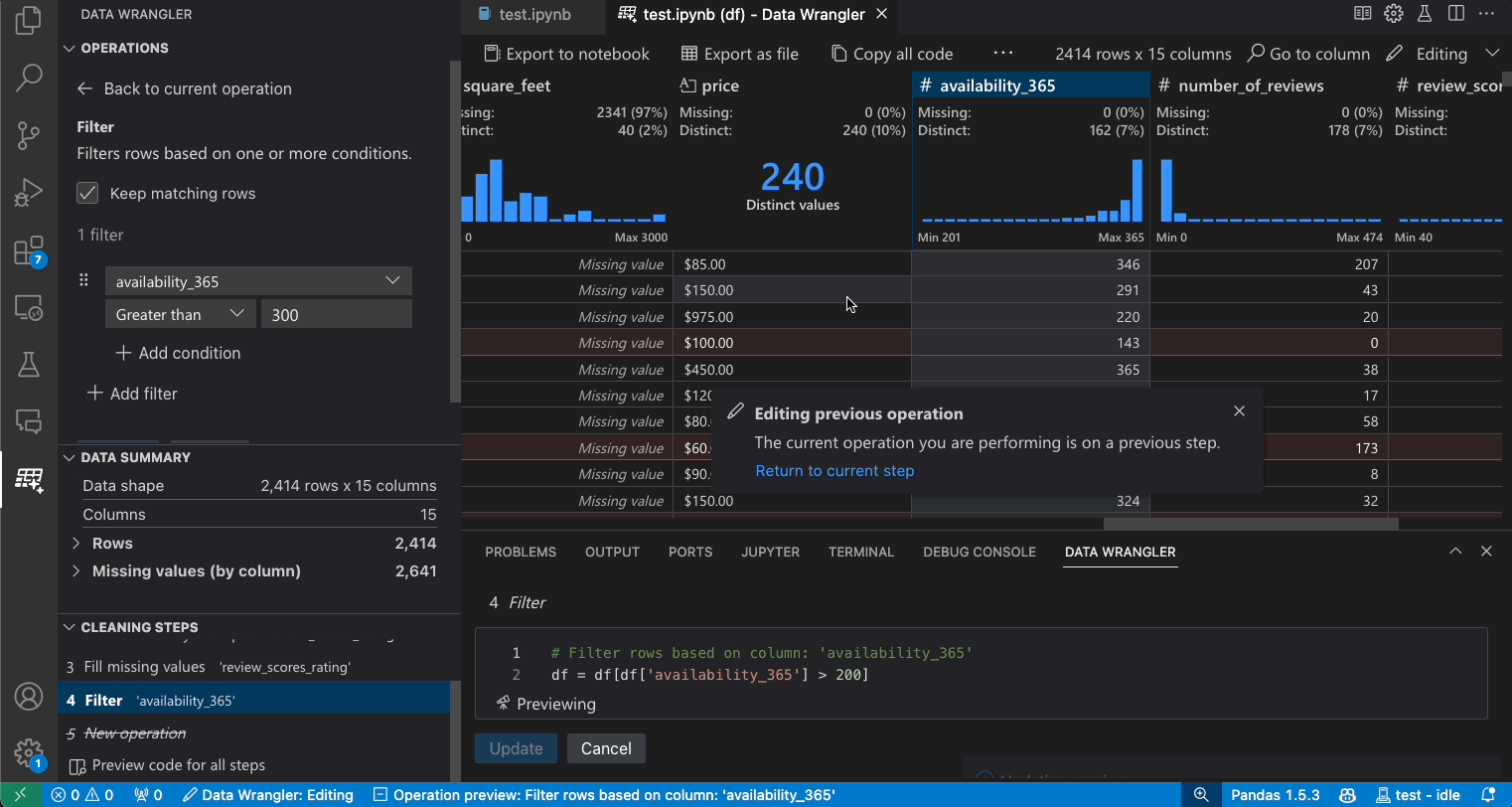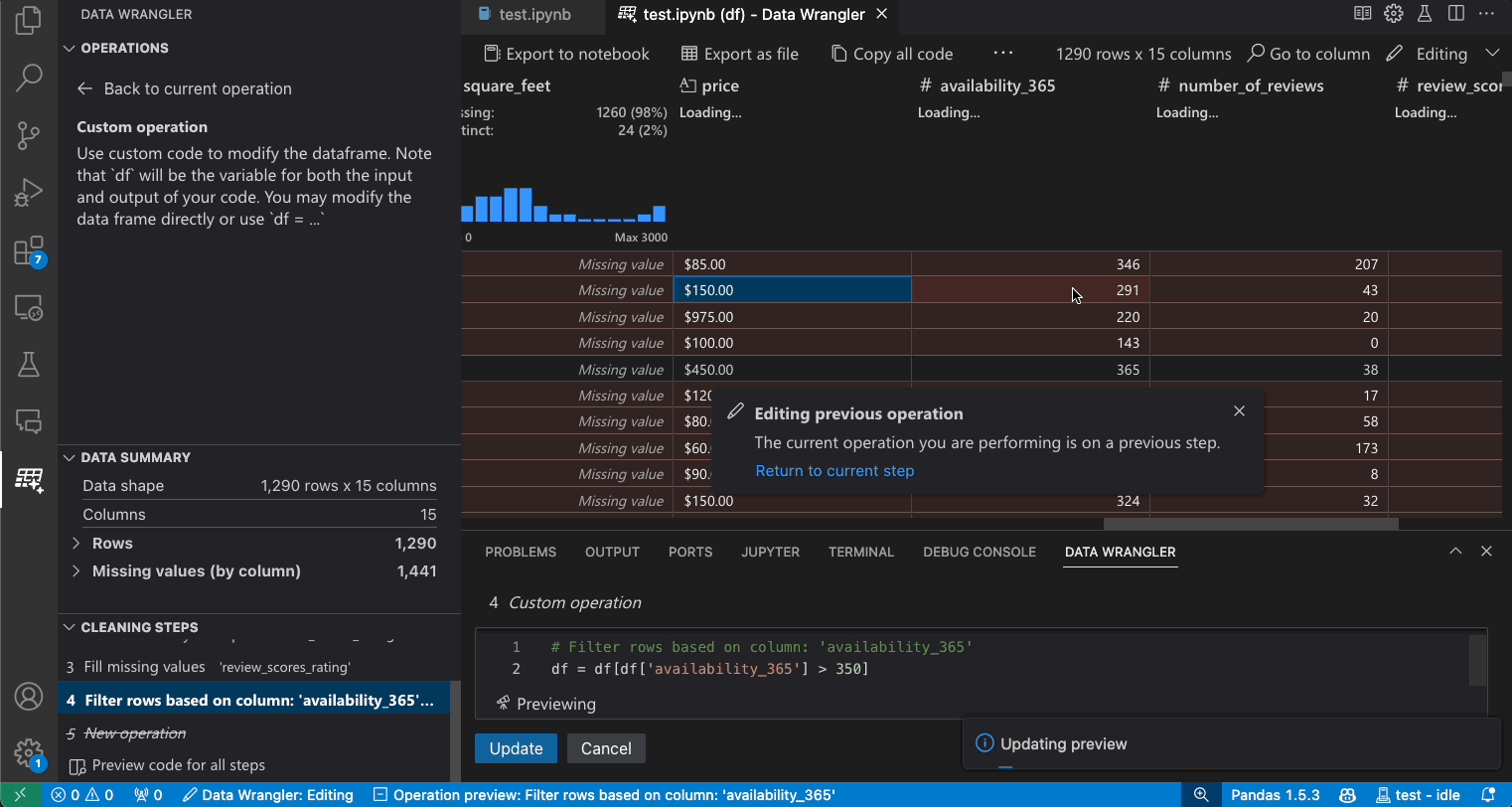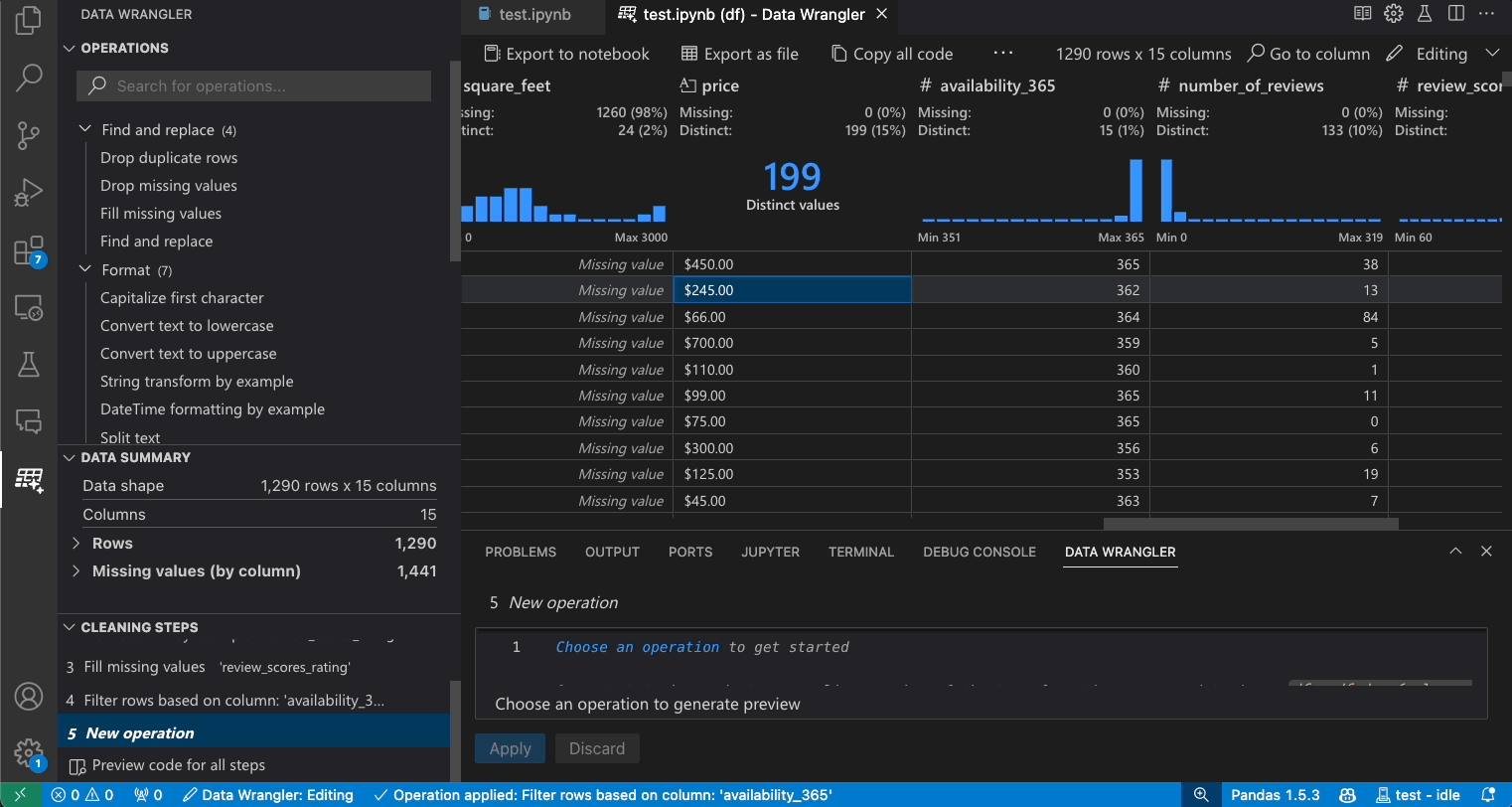
이전 단계 수정
생성된 코드의 각 단계는 정리 단계 패널을 통해 수정할 수 있습니다. 먼저 수정하려는 단계를 선택합니다. 그런 다음 코드를 통해 또는 작업 패널을 통해 작업을 변경하면 데이터 그리드에서 변경 사항의 영향이 강조 표시됩니다.
코드 편집 및 내보내기
Data Wrangler에서 데이터 정리 단계를 완료하면 Data Wrangler에서 정리된 데이터 세트를 내보내는 세 가지 방법이 있습니다.
- Notebook으로 코드 다시 내보내고 종료: 이렇게 하면 Jupyter Notebook에 생성된 모든 데이터 정리 코드가 Python 함수로 패키지화된 새 셀이 생성됩니다.
- 파일로 데이터 내보내기: 정리된 데이터 세트를 CSV 또는 Parquet 파일로 컴퓨터에 저장합니다.
- 클립보드로 코드 복사: Data Wrangler에서 데이터 정리 작업을 위해 생성한 모든 코드를 복사합니다.
열 검색
데이터 세트에서 특정 열을 찾으려면 Data Wrangler 도구 모음에서 열로 이동을 선택하고 해당 열을 검색합니다.
문제 해결
일반 커널 연결 문제
일반적인 연결 문제의 경우 대체 연결 방법에 대해 위의 "Python 커널에 연결" 섹션을 참조하세요. 로컬 Python 인터프리터 옵션과 관련된 문제를 디버그하려면 문제 해결의 한 가지 방법은 Jupyter 및 Python 확장의 다른 버전을 설치하는 것입니다. 예를 들어, 안정 버전의 확장이 설치되어 있다면 미리 보기 버전을 설치할 수 있습니다(또는 그 반대).
이미 캐시된 커널을 지우려면 명령 팔레트 ⇧⌘P (Windows, Linux Ctrl+Shift+P)에서 Data Wrangler: Clear cached runtime 명령을 실행할 수 있습니다.
데이터 파일을 열 때 UnicodeDecodeError 발생
Data Wrangler에서 직접 데이터 파일을 열 때 UnicodeDecodeError가 발생하는 경우 두 가지 가능한 문제가 원인일 수 있습니다.
- 열려는 파일의 인코딩이
UTF-8이 아님 - 파일이 손상됨.
이 오류를 해결하려면 데이터 파일에서 직접 Data Wrangler를 여는 대신 Jupyter Notebook에서 Data Wrangler를 열어야 합니다. Jupyter Notebook을 사용하여 Pandas로 파일을 읽고, 예를 들어 read_csv 메서드를 사용합니다. read 메서드 내에서 encoding 및/또는 encoding_errors 매개변수를 사용하여 사용할 인코딩이나 인코딩 오류를 처리하는 방법을 정의합니다. 이 파일에 어떤 인코딩이 작동할지 모르는 경우 chardet와 같은 라이브러리를 사용하여 작동하는 인코딩을 추론해 볼 수 있습니다.
질문 및 피드백
문제가 발생하거나, 기능 요청 또는 기타 피드백이 있는 경우 GitHub 저장소에 이슈를 제출해 주세요: https://github.com/microsoft/vscode-data-wrangler/issues/new/choose
데이터 및 원격 분석
Microsoft Data Wrangler Visual Studio Code 확장은 사용량 데이터를 수집하여 Microsoft에 전송하여 제품 및 서비스를 개선하는 데 도움을 줍니다. 자세한 내용은 개인 정보 취급 방침을 읽어보세요. 이 확장은 telemetry.telemetryLevel 설정을 존중하며, 이에 대한 자세한 내용은 https://vscode.gisul.kr/docs/configure/telemetry에서 확인할 수 있습니다.